
Transfer learning может стать отличным решением, когда нет больших вычислительных ресурсов для обучения моделей Machine Learning, а также когда нет достаточного количества данных. Это также касается задач компьютерного зрения (Computer vision). Не секрет, что сбор, хранение, разметка и другие виды обработки изображений затратны, а ещё необходимо обучить модель. Тогда на помощь могут придти модели, предварительно обученные на миллионах изображений. Сегодня мы расскажем о 4 таких моделях машинного обучения ( VGG-19, Inceptionv3, ResNet50, EfficientNet), которые можно использовать для задач компьютерного зрения.
Подсчет точности: Top-1 vs Top-5
Ниже мы будем указывать оценку точности моделей машинного обучения, используя терминологию Top-1 и Top-5. Чтобы было понятно о чем речь, обговорим эти меры точности.
Top-1 считает ответ верным только тогда, когда наиболее вероятный ответ модели совпадает с правильным. Топ-5 означает, что правильный ответ попал в один из 5 наиболее вероятных ответов.
Рассмотрим пример, когда нейронной сети (Neural Net) нужно определить класс животного по картинке. Допустим, нейронной сети показывается изображение кошки, и она выдает ответ в виде:
- Тигр: 0.4
- Собака: 0.3
- Кошка: 0.1
- Рысь: 0.09
- Лев: 0.08
- Птица: 0.02
- Медведь: 0.01
С точки зрения Top-1 ответ модели неверный, так как наиболее вероятный предсказанный ответ — это тигр. А вот Top-5 говорит, что ответ модели верный, так как кошка среди 5 лучших ответов.
1. VGG-19
VGG-19 — сверточная нейронная сеть (CNN), которая имеет 19 главных слоев (16 сверточных, 3 полносвязных) а также 5 слоев MaxPool и 1 слой SoftMax. Она была сконструирована и обучена в Оксфордском университете в 2014 году. Более подробно о ней можно узнать из статьи «Очень глубокие сверточные сети для распознавания крупномасштабных изображений (англ. Very Deep Convolutional Networks for Large-Scale Image Recognition» [1].
Для обучения сети VGG-19 использовалось более чем 1 миллиона изображений из базы данных ImageNet. Естественно, можно импортировать модель с обученными весами от ImageNet. Эта предварительно обученная сеть может классифицировать до 1000 объектов. Сеть обучалась на цветных изображениях размером 224×224 пикселей. Вот краткая информация о его размере и производительности VGG-19:
- Размер: 549 MB
- Top-1: 71.3%
- Top-5: 90.0%
- Количество параметров: 143,667,240
- Общее количество слоев: 25
2. Inceptionv3 (GoogLeNet)
Inceptionv3 — это сверточная нейронная сеть, имеющая глубину в 50 основных слоев. Она была создана и обучена в Google [2]. Предварительно обученная модель Inceptionv3 с весами ImageNet может также классифицировать до 1000 объектов. Размер входного изображения этой сети составляет 299×299 пикселей, что больше, чем у сети VGG19. В 2014 году на соревнованиях от ImageNet, где решалась задачи детектирования, классификации и локализации объектов на изображении, сеть VGG19 заняла второе место, а сеть Inception стала победителем. Краткое описание возможностей Inceptionv3 выглядит следующим образом:
- Размер: 92 MB
- Top-1: 77.9%
- Top-5: 93.7%
- Количество параметров: 23,851,784
- Общее количество слоев: 159
3. ResNet50 (Residual Network)
ResNet50 — это CNN, которая имеет 50 основных слоев (сверточные + полносвязные). Сеть ResNet50 была разработана в Microsoft в 2015 году для решения задачи распознавания изображений [3]. Эта модель Machine Learning также обучена на более чем 1 миллионе изображений из базы данных ImageNet. Как и предыдущие модели, ResNet50 может классифицировать до 1000 объектов. Принимает на вход цветные изображения размером 224×224 пикселей. Данная сеть была разработана с целью избавиться от затухающих и взрывных градиентов. Краткие характеристика ResNet50:
- Размер: 98 MB
- Top-1: 74.9%
- Top-5: 92.1%
- Количество параметров: 25,636,712
- Общее количество слоев: 176
Несмотря на то, что сеть ResNet50 имеет меньше параметров, она показывает более высокие результаты, чем VGG19.
4. EfficientNet
Модель EfficientNet была опубликована в 2019 году компанией Google и является одной из самых современных разработок (state-of-the-art ) [4]. Авторы модели выяснили взаимосвязь между точностью и размером модели. Так, они установили, что точность модели CNN увеличивается вместе с увеличением ширины (количества фильтров в каждом слое), глубины (количество слоев в модели) и разрешения (размер входного изображения). Тем не менее, увеличивая глубину, ширину и высоту слоев пропорционально степени N, вычислительные затраты увеличатся со степени 2 до степени N. Поэтому и были созданы разное семейство архитектур EfficientNet, которые имеют разное количество параметров.
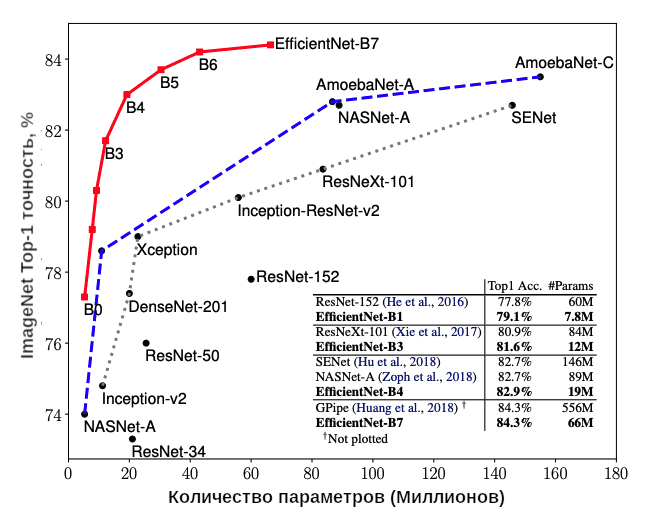
Существует 8 реализаций EfficientNet, отсчитывающихся от B0 до B7 по мере увеличения сложности архитектуры. Тем не менее, даже самый простой EfficientNetB0 показывает хорошие результаты. При наличие всего лишь 5,3 миллионов параметров, он обеспечивает точность 77,1% (Top-1), поэтому дообучение (fine-tuning) модели машинного обучения не займет много времени. Так, краткие характеристики EfficientNetB0 выглядят следующим образом:
- Размер: 29 MB
- Top-1: 77.1 %
- Top-5: 93.3 %
- Количество параметров: ~5,300,000
- Общее количество слоев: 158
Также смотрите видеоролик о том, как проводить сегментацию изображений в TensorFlow, используя обученные модели.
А о том, как использовать существующие модели Machine Learning для решения задач компьютерного зрения, а также о том, как применять дообучение с использованием современных Python-фреймворков, вы узнаете на нашем специализированном курсе «VISI: Computer Vision» в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.

