Сonvolutional neural network (CNN, ConvNet), или Сверточная нейронная сеть — класс глубоких нейронных сетей, часто применяемый в анализе визуальных образов. Сверточные нейронные сети являются разновидностью многослойного перспептрона с использованием операций свёртки. Они нашли применение в распознавании изображений и видео, рекомендательных системах, классификации изображений, NLP (natural language processing) и анализе временных рядов.
Принцип работы операции свертки
Операцию свёртки можно представить следующим алгоритмом:
- Скользящее окно, называемое фильтром, с размером (n,n) двигается по входному признаку. Количество движений определяется заданным количеством фильтров.
- Каждый полученный шаблон имеет форму (n,n,d), где d — глубина входного признака.
- Каждый шаблон умножается на своё ядро свёртки, в результате, формируется выходная карта признаков. Полученная выходная карта признаков имеет форму (h,w,N), где h и w — длина и ширина, полученные в результате отсечения, а N — количество фильтров.
Количество фильтров — гиперпараметр, поэтому выбирается самостоятельно. Обычно его подбирают как степень двойки с увеличением количества фильтров по мере увеличения глубины архитектуры. А ядра свёртки являются обучаемыми параметрами.
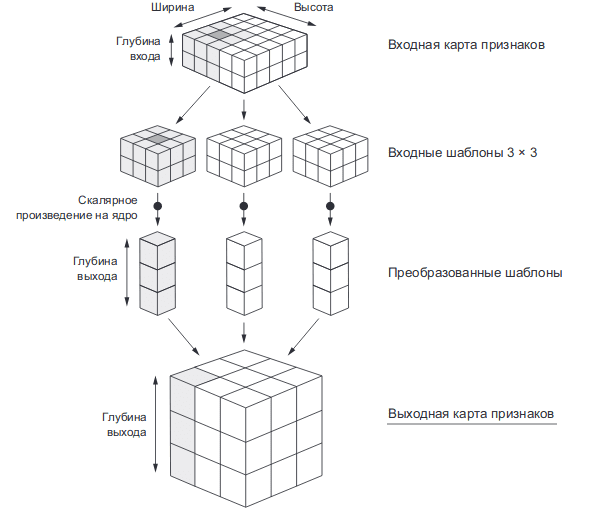
Рассмотрим процесс свёртки на примере изображения в оттенках серого с размером (28,28). Глубина изображения в оттенках серого равна 1, если бы это было RGB, то глубина входа равнялась бы 3. Пусть размер фильтра равняется (3,3), а всего их 32.
- На первом этапе сформируются 32 шаблона размером (3,3,1), где 1 — глубина изображения.
- Полученные шаблоны умножаются на ядра свертки. Каждый преобразованный в результате умножения шаблон формирует вектор с длиной равной количеству фильтров, т.е. 32.
- Все преобразованные шаблоны объединяются в выходную карту признаков. Она имеет размер (26,26,32)
Почему уменьшается размерность после операции свёртки
В рассмотренном выше примере выходная карта признаков имеет размерность (26,26,32), в то время как исходное изображение имело размерность (28,28,1). Если 32 — количество фильтров, а 1 — глубина входа, тогда почему исходный размер 28 уменьшился до 26?
Рассмотрим матрицу (5,5) и фильтр (3,3). Дело в том, что центр скользящего окна может встать только в 9 клеток матрицы (5,5) , как это показано на рисунке ниже. Следовательно, после умножения на ядра свёртки сформируется выходная карта признаков с высотой и шириной (3,3).
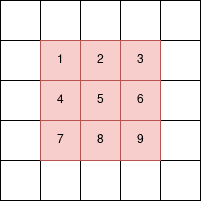
Для фильтра с размером (5,5) исходное изображение (28,28) уменьшилось бы в (24,24). Иногда такого обрезания можно избежать путём эффекта дополнения (padding). Он заключается в добавлении строк и столбцов так, что центр скользящего окна можно поместить в каждую клетку. Для фильтра (3,3) добавляются строки сверху и снизу и столбцы слева и справа. Для фильтра (5,5) добавляются по 2 строки снизу и сверху и 2 столбца слева и справа.
Слой Pooling
В сверточных нейронных сетях применяется ещё один слой, называемый слоем Pooling. Суть этого слоя заключается в уменьшении размерности карты признаков.
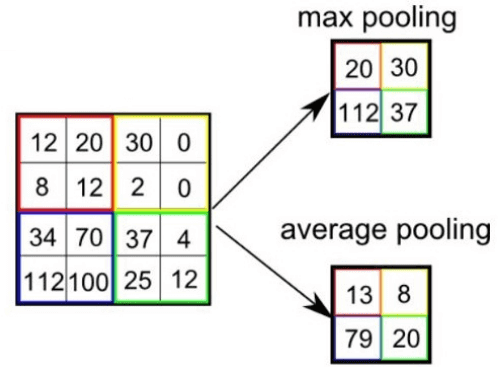
Pooling имеет две разновидности: max-pooling и average-pooling. В большинстве случаев применяется max-pooling. Операция Pooling схожа с операцией свертки:
- Скользящее окно, обычно это окно (2,2), двигается по карте признаков.
- Из выбранного шаблона выбирается максимальное (max-pooling) или среднее (average-pooling) значение.
- Формируется уменьшенная в размере карта признаков.
На рисунке ниже показано, как из матрицы (4,4) получается выходная карта (2,2) после операции max-pooling и average-pooling.
Зачем нужно уменьшать размерность с помощью Pooling? На это есть несколько причин:
- Для поддержания иерархичности. Архитектура сверточных нейронных сетей похожа на воронку, где все начинается с большой картины с последующим углублением в отдельные детали. Человеческий мозг устроен также: сначала он видит на улице кошку, а затем начинает разглядывать ее цвет, пятна, уши, глаза и т.д. Это является основой Deep learning — обучение на представлениях.
- Уменьшение размерности приводит к уменьшению количества обучаемых коэффициентов, поэтому это ещё и выигрыш в вычислительных ресурсах.
Свойства сверточных нейронных сетей
Сверточные нейронные сети смогли завовоевать свою популярность благодаря соответствию иерархичности представлений, поскольку изучаются локальные шаблоны. У CNN есть несколько свойств:
- Полученные представления являются инвариантными по отношению к переносу. На изображении кошка может находиться в любом доступном месте, а сверточная сеть не запоминает её положения, CNN лишь знает о её представлениях (ушах, глазах и т.д.)
- Модель CNN является пространственно-иерархической. На первых слоях изучаются локальные шаблоны, а последующие изучают шаблоны, полученные из первых слоев.
Архитектура CNN для задачи классификации
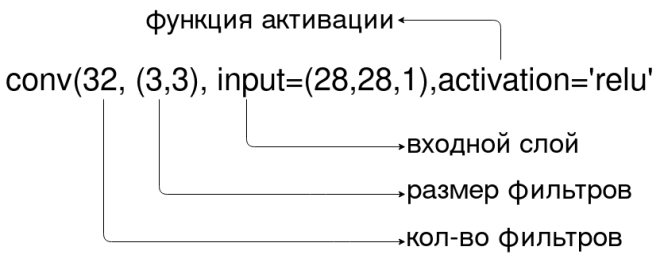
В TensorFlow архитектура сверточной нейронной сети для классификации изображений в Python может выглядеть следующим образом [1]:
model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10))
В конце последнего сверточного слоя видно, что есть слой выпрямления (Flatten), поскольку выходной признак — это трехмерный признак. После выпрямления стоят полносвязные слои (Dense) уже для классификации.
Читайте также:
- Deep Learning
- Краткий обзор TensorFlow
- Сверточные нейронные сети в TensorFlow
- Соединяем архитектуру VGG16 со своим классификатором в TensorFlow
- Как повысить точность классификатора с Transfer Learning