Компьютерное зрение (Computer vision) — это междисциплинарная научная область, целью которой является создание и изучение компьютерных систем, обладающих общим высокоуровневым представлением о цифровых изображениях или видео. С практической точки зрения компьютерное зрение стремится понять и автоматизировать задачи, которые может выполнять зрительная система человека.
В машинном обучении computer vision реализуется за счёт сверточных нейронных сетей (CNN) для решения задач сегментации, классификации, детектирования, обработки изображений и проч.
Как сверточные нейронные сети сделали революцию в области computer vision
В 1989 году Ян ЛеКун использовал метод обратного распространения ошибки в сверточной нейронной сети (CNN) [1]. Эта сеть состояла из нескольких слоев с искусственными нейронами. Каждый слой ответственен за свои локальные представления. С увеличением глубины слоев, локальные представления нейронной сети становятся более абстрактными и специфичными, что помогает изучить детали отдельного класса. Также сверточная нейронная сеть обладает свойством инвариантности, т.е. не запоминает местоположение объектов на изображении. Однако на тот момент времени из-за нехватки данных и компьютерных ресурсов CNN не показали высокой точности.
В 2012 году исследователи из Торонто разработали AlexNet, сверточную нейронную сеть, которая обогнала все другие модели компьютерного зрения в соревнованиях от ImageNet [2]. Победа AlexNet дала понять — пришло время вернуться к CNN. С учетом доступности данных и вычислительных ресурсов данное событие возродило интерес к CNN и вызвало революцию в глубоком обучении (Deep Learning). После этого появлялись ещё много разных моделей глубокого обучения: ResNet, Xception, Inception, EfficientNet и многие другие.
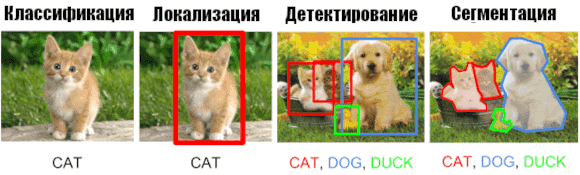
4 задачи распознавания образов
Большинство решаемых задач по распознаванию образов в компьютерном зрении сводится к следующим 4 задачам :
- Классификация. Нейронные сети можно обучить, например, идентифицировать собак или кошек с высокой степенью точности при наличии таких изображений.
- Локализация необходима для определения местоположения объектов. Обычно найденные объекты ограничиваются в прямоугольники.
- Детектирование, когда алгоритмы Machine Learning не только находят объект на изображении, но и проводят классификацию.
- Сегментация — это отнесение пикселей к определенной категории, например автомобилю, дороге или пешеходу. В отличие от детектирования, подсвечивается лишь те пиксели, которые принадлежат объекту.
Как правило, для решения вышеперечисленных задач используются модели машинного обучения с применением сверточных нейронных сетей. Точность этих моделей проверяется на конкурсе ImageNet, в котором предлагается вычислить 1000 классов [3]. Многие модели испытывают трудности с распознаванием мелких объектов, например, насекомых, а также трудности появляются с теми изображениями, которые искажены фильтрами.
Из задач распознавания образов вытекают ещё дополнительные задачи:
- Поиск изображений по контексту (Content-based image retrieval) — поиск всех изображений в большом наборе данных определенного контекста. Контекст может быть указан по-разному: по сходству относительно целевого изображения (найти все изображения, похожие на изображение X) или по критерию поиска, заданного в виде текста (найти все изображения, которые содержат много домов, на улице зима, машин нет).
- Определение положения (Pose estimation) — оценка положения или ориентации определенного объекта относительно камеры. Примером применения этого метода может быть робот-манипулятор, который извлекает объекты с конвейерной ленты на сборочной линии, подстраиваясь под них.
- Оптическое распознавание символов (OCR) — идентификация символов на изображениях печатного или рукописного текста, обычно с целью кодирования текста в формате, более удобном для редактирования или индексации (например, ASCII).
- Распознавание лиц.
- Технология распознавания форм (Shape Recognition Technology, SRT), которую можно наблюдать в приложениях, которые понимают, что рисует человек (т.н., это может быть иероглиф, прямоугольник, круг или животное).
Работа с видео и 3D
Ещё одним примером использования computer vision является анализ видеопотоков. Задача усложняется если все это происходит в реальном времени, поэтому тяжеловесные модели не подойдут. Так, на основе видеоданных могут решаться такие задачи как:
- Слежение — отслеживание движений меньшего набора точек или объектов (например, транспортных средств, людей или других организмов).
- Определение трехмерного движения камеры (Egomotion). Эта задача относится к оценке движения камеры относительно заданной сцены. Например, оценка движущегося положения автомобиля относительно линий на дороге или уличных знаков, наблюдаемых с самого автомобиля.
Читайте также:
- CNN
- Сверточные нейронные сети в TensorFlow
- ТОП-4 моделей машинного обучения для компьютерного зрения
А также в нашем видеоролике узнаете о решении задачи обнаружения объектов на изображении с использованием Python-фреймворка TensorFlow:
Источники