В прошлой статье мы рассматривали и даже реализовывали собственноручно такой метод классификации как дерево решений, сегодня будем разбираться с алгоритмом который базируется на деревьях решений– случайный лес (Random Forest).
Что такое Random Forest?
Random Forest (случайный лес) – это алгоритм машинного обучения, который используется для решения задач классификации и регрессии. Он является расширением алгоритма решающих деревьев, который использует ансамбль деревьев для улучшения качества классификации или регрессии.
Суть алгоритма заключается в том, что он создает множество решающих деревьев и использует их для предсказания классов объектов. Каждое дерево строится на случайном подмножестве обучающих данных и случайном подмножестве признаков. В результате, каждое дерево в ансамбле получается немного разным, что позволяет уменьшить эффект переобучения и повысить качество предсказаний.
Для построения каждого дерева случайного леса происходит следующее:
- Случайным образом выбирается подмножество обучающих объектов (bootstrap sample) из всего набора данных. Этот подмножество может содержать повторяющиеся объекты.
- Случайным образом выбирается подмножество признаков (обычно корень квадратный от общего числа признаков). Это позволяет уменьшить корреляцию между деревьями в ансамбле и улучшить их разнообразие.
- Строится дерево решений на выбранном подмножестве данных и признаков. При построении дерева используется критерий информативности (например, энтропийный критерий), который позволяет выбрать наилучший признак для разбиения данных на каждом уровне дерева.
- Повторяем шаги 1-3 для каждого дерева в ансамбле.
После построения всех деревьев в ансамбле, для каждого объекта данных происходит голосование по всем деревьям, и наиболее популярный класс становится предсказанным классом. В случае задачи регрессии, результаты всех деревьев усредняются, и это усредненное значение становится предсказанием.
Одно из главных преимуществ Random Forest заключается в том, что он позволяет оценить важность каждого признака для классификации объектов. Это можно сделать, используя атрибут feature_importances_ модели, который возвращает массив значений, отражающих важность каждого признака. Более важные признаки будут иметь более высокие значения.
Важно заметить, что Random Forest менее подвержен проблеме переобучения (overfitting) , что является одной из основных проблем в задачах машинного обучения. Это связано с тем, что каждое дерево строится на случайном подмножестве данных и признаков, что позволяет уменьшить корреляцию между деревьями и повысить их разнообразие.
Еще одним преимуществом Random Forest является его способность обрабатывать большое количество признаков и работать с данными различных типов (например, числовые, категориальные, текстовые). Кроме того, модель не требует сложной предобработки данных и может работать с пропущенными значениями.
Существует несколько параметров, которые можно настраивать при использовании Random Forest, например, количество деревьев в ансамбле, количество объектов и признаков в каждом подмножестве, критерий информативности, максимальную глубину деревьев и т.д. Настройка этих параметров может помочь улучшить качество модели и снизить вероятность переобучения.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
29 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000 руб.
Реализация Random Forest на Python
Так как Random Forest, это ансамбль деревьев решений, воспользуемся классом который реализует дерево решений, который мы реализовали в прошлой статье. Для начала импортируем всё библиотеки, которые нам пригодятся. Дерево решений я так же запаковал в .py файл и буду использовать здесь как библиотеку:
import numpy as np import matplotlib.pyplot as plt from sklearn import svm, datasets from sklearn.metrics import accuracy_score from sklearn.datasets import make_classification from sklearn.metrics import classification_report from My_DecisionTree import DecisionTree # Класс реализованный в прошлой статье
Далее реализуем класс для обучения алгоритма леса решений:
class RandomForestClassifier:
def __init__(self, n_estimators=100, max_depth=None, random_state=None):
# Конструктор класса, устанавливающий параметры модели
self.n_estimators = n_estimators # количество деревьев в лесу
self.max_depth = max_depth # максимальная глубина деревьев
self.random_state = random_state # случайное начальное состояние для генератора случайных чисел
self.estimators = [] # список для хранения деревьев
def fit(self, X, y):
# Метод для обучения модели на тренировочных данных X и метках y
rng = np.random.default_rng(self.random_state) # инициализация генератора случайных чисел
for i in range(self.n_estimators):
# Использование Bootstrap Aggregating для случайного выбора объектов для текущего дерева
idxs = rng.choice(X.shape[0], X.shape[0])
X_subset, y_subset = X[idxs], y[idxs]
# Создание и обучение дерева решений с заданными параметрами
clf = DecisionTree(max_depth=self.max_depth)
clf.fit(X_subset, y_subset)
self.estimators.append(clf) # Добавление обученного дерева в список
def predict(self, X):
# Метод для предсказания меток на новых данных X
y_pred = []
for i in range(len(X)):
votes = {} # Словарь для подсчета голосов деревьев за каждый класс
for clf in self.estimators:
pred = clf.predict([X[i]])[0] # Предсказание метки на текущем дереве
if pred not in votes:
votes[pred] = 1
else:
votes[pred] += 1
y_pred.append(max(votes, key=votes.get)) # Выбор метки с наибольшим количеством голосов
return np.array(y_pred) # Возвращение предсказанных меток в виде массива numpy
Далее обучим и оценим точность нашего алгоритма:
# Генерируем данные для обучения
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_informative=2,
random_state=1, n_clusters_per_class=1)
clf = RandomForestClassifier(n_estimators=100, max_depth=3)
clf.fit(X, y)
# Прогнозируем метки классов
y_pred = clf.predict(X)
print(classification_report(y, y_pred))
OUT:
precision recall f1-score support
0 0.91 0.94 0.93 500
1 0.94 0.91 0.92 500
accuracy 0.93 1000
macro avg 0.93 0.93 0.92 1000
weighted avg 0.93 0.93 0.92 1000
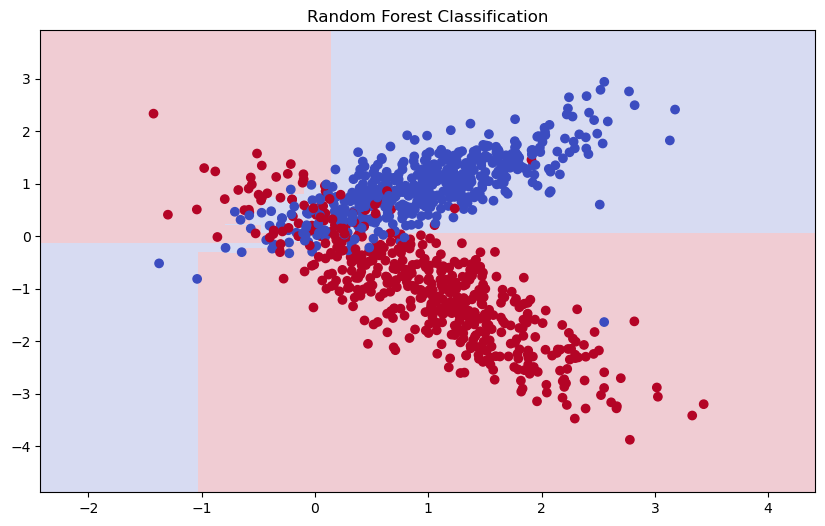
Как видим, если сравнивать с результатами классификации одним деревом, которые мы получили в прошлой статье, лес решений справляется лучше.
Далее визуально оценим как принимает решение наш алгоритм:
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
29 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000 руб.
Random Forest является мощным алгоритмом машинного обучения, имеющим как свои преимущества, так и недостатки.
Плюсы:
- Модель может использоваться для задач классификации и регрессии.
- Способность обрабатывать данные с большим количеством признаков.
- Имеет возможность обрабатывать отсутствующие значения.
- Способность обрабатывать шумные и нелинейные данные.
- Модель является достаточно устойчивой к переобучению.
- Способность измерять важность каждого признака для задачи.
Минусы:
- Модель может быть сложной для интерпретации, так как она объединяет множество деревьев решений.
- Потребность в настройке гиперпараметров, таких как количество деревьев и глубина каждого дерева.
- Для обучения модели может потребоваться большое количество времени и вычислительных ресурсов, особенно при использовании большого количества деревьев.
Если вы хотите углубить свои знания в области машинного обучения на языке Python и быть в курсе последних методов и инструментов, мы рекомендуем посетить наш лицензированный учебный центр в Москве, специализирующийся на обучении ИТ-специалистов. Там вы можете пройти практический курс «Машинное обучение на Python«.
Источники:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html

