В мире Deep Learning существует множество видов нейронных сетей, которые используются в разных областях Data Science. В этой статье мы расскажем о 12 типах нейронных сетей, а также о их применении в решении практических задач. Вторая часть содержит еще 11 продвинутых архитектур.
1. Перцпетрон
Модель перцептрона (Perceptron) также известна как однослойная нейронная сеть состоит всего из двух слоев:
- Входной слой (Input Layer)
- Выходной слой (Output Layer)
Перцептрон принимает входные данные и вычисляет веса каждого нейрона. После этого линейная комбинация весов передается функции активации (сигмоидальная функция) для классификации.
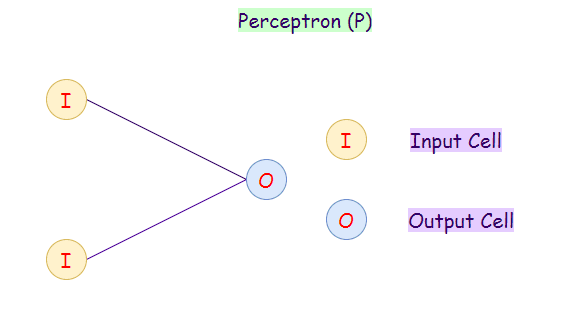
Перцептрон является первой моделью нейронных сетей. Добавление скрытых слоев сделает из модели многослойный перцептрон.
2. Сеть прямого распространения (FF)
Сеть прямого распространения (Feed Forward) — это искусственная нейронная сеть, в которой нейроны никогда не образуют цикла. В этой нейронной сети все нейроны расположены в слоях, где входной слой принимает исходные данные, а выходной слой генерирует результат в заданном виде. Помимо входного и выходного слоев, есть еще скрытые слои — это слои, которые не имеют связи с внешним миром. В нейронной сети прямого распространения каждый нейрон одного слоя связан с каждым нейроном на следующем слое. Слои с такими нейронами называются полносвязными (fully-conected, dense).
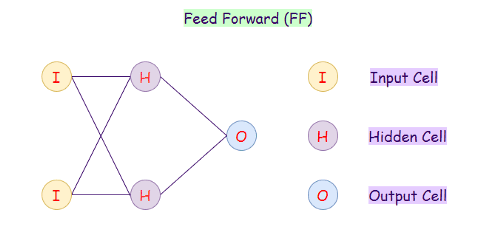
Увеличение числа скрытых слоев делает из нее глубокую нейронную сеть прямого распространения (Deep Feed-forward, DFF). Для обновления значений весов используется алгоритм обратного распространения ошибки (backpropagation).
Применение DFF и FF:
- Сжатие данных
- Распознавание образов
- Компьютерное зрение (Computer vision)
- Распознавание речи
- Распознавание рукописных символов
3. Сеть радиальных базисных функций (RBFN)
Сеть радиальных базисных функций (radial basis function network, RBFN) обычно используются для задач аппроксимации. Эта сеть обладает высокой скоростью обучения. Архитектура такая же как и у сети прямого распространения (см. рисунок выше), но основное различие состоит в том, что RBFN использует радиально-базовую функцию в качестве функции активации.
RBFN определяет, насколько далеко сгенерированный результат радиально-базовой функции находится от целевого значения.
Применение RBFN:
- Аппроксимация функций
- Прогнозирование временных рядов
- Классификация
- В системах автоматического управления
4. Рекуррентные нейронные сети (RNN)
В рекуррентных нейронных сетях (Recurrent Neural Network, RNN) каждый из нейронов в скрытых слоях получает на вход данные с определенной задержкой во времени. Также рекуррентная нейронная сеть обладает состоянием, приобретенное при обработки предыдущих элементов последовательности. Это можно сравнить со случаем, если мы пытаемся предсказать следующее слово в предложении, то нам нужно сначала узнать предыдущие слова. RNN имеют внутренние циклы (петли), поэтому решение выносится при учете самих данных, а также текущего состояния сети.
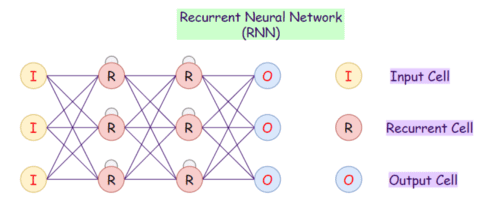
Проблема этой нейронной сети — низкая скорость обучения. А также она не хранит давнюю информацию, т.е. не работает с учетом долгосрочной перспективы. Обычная рекуррентная сеть, как и перцептрон, нужна скорее для проектирования более сложных архитектур (LSTM, GRU).
5. Долгая краткосрочная память (LSTM)
При большом объеме данных RNN становятся просто непригодными, поскольку запоминают скорее последнюю информацию и забывают о информации, полученной давным-давно. Эта проблема схожа с затухающими градиентами в сетях прямого распространения. Поэтому на замену обычным рекуррентным сетям приходит сеть с долгой краткосрочной памятью (Long Short-Term Memory, LSTM).
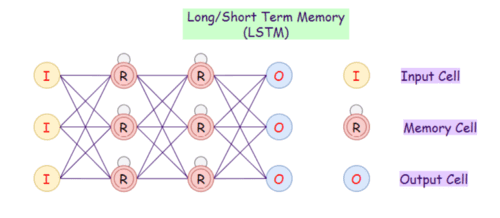
Нейронные сети LSTM обладают памятью, т.е. текущая информация сохраняется для последующего использования в будущем. LSTM является революционной технологией, которая используется во многих приложениях, например, в виртуальном ассистенте Siri от Apple.
Применение LSTM:
- Распознавание речи
- Оптическое распознавание символов
- Генерация текстов
- Прогнозирование временных рядов
- Машинный перевод
- Вопросо-ответная система, чат-боты и NLP
6. Управляемые рекуррентные нейроны (GRU)
Управляемый рекуррентный блок (Gated Recurrent Unit, GRU) — это разновидность LSTM. Сеть GRU имеет два вентиля (сброса и обновлений), в то время как у LSTM их три (входной, выходной и вентиль забывания). Поэтому архитектура и применение такие же, поскольку отличия только во внутренней реализации.
GRU использует меньше параметров обучения и, следовательно, использует меньше вычислительных ресурсов, выполняется и обучается быстрее, чем LSTM. Если входная последовательность большая или точность очень важна, то обычно используется LSTM, тогда как для меньшего потребления памяти и более быстрой работы используется GRU.
7. Сверточные нейронные сети (CNN)
Сверточные нейронные сети (Convolutional Neural Network, CNN) — это нейронные сети, которые показали высокую точность в классификации и кластеризации изображений, а также в распознавании объектов, хотя применяется практически везде. CNN состоят из двух видов слоев: слои свертки и пулинга. Слой пулинг необходим для уменьшения размерности. Преимущество сверточных сетей заключается в их свойстве инвариантности, т.е. объект на изображении может находиться в любом месте, но сеть его все равно найдет.
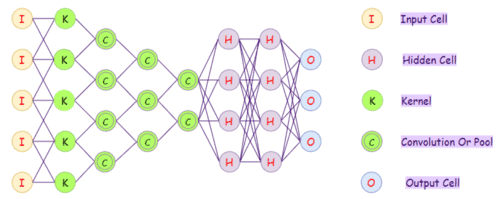
Применение CNN:
- Распознавание образов
- Компьютерное зрение (computer vision)
- Видеоанализ
- NLP
8. Деконволюционные сети
Деконволюционные сети (Deconvolutional Neural Networks, DNN) — это сверточные нейронные сети, которые работают в обратном процессе. Несмотря на то, что DNN похожа на CNN по характеру работы, его применение в ИИ сильно отличается. Деконволюционные сети стремятся дополнить признаки или сингалы, которые ранее могли не считаться важными для задачи сверточной нейронной сети. Деконволюция сигналов может использоваться как для синтеза, так и для анализа изображений.
Применение DNN:
- Сегментация
- Генерация изображений
9. Автоэнкодер
Автоэнкодер (Autoencoder) — это еще одна разновидность сетей прямого распространения. Его цель восстановить входной сигнал на выходе. Поэтому автоэнкодеры используют для нахождения общих закономерностей в данных, а также для восстановления исходных данных из сжатых.
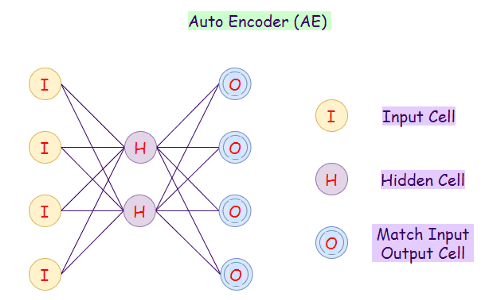
Типичный автоэнкодер имеет скрытый слой, который является мостом между кодированием и декодированием.
Применение автоэнкодеров:
- Классификация
- Кластеризация
- Сжатие данных
10. Вариационный автоэнкодер
Вариационный автоэнкодер (Variational Autoencoder) использует вероятностный подход для описания наблюдений. Он показывает распределение вероятностей для каждого атрибута в наборе функций.
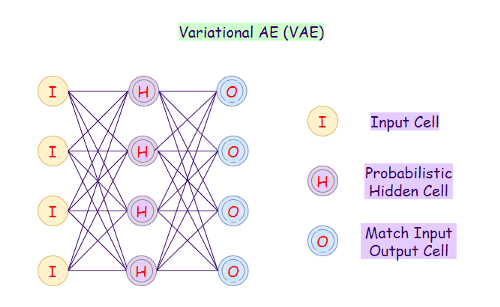
Применение вариационного автоэнкодера:
- Интерполяция и аппроксимация
- Автоматическая генерация изображений
11. Шумоподавляющий автоэнкодер
Если количество нейронов в скрытом слое равно или больше, чем во входном слое, то может произойти проблема идентификации. Она возникает когда то, что отправили на вход, то получили на выходе. Такой автоэнкодер бесполезен.
Эту проблему решает шумоподавляющий автоэнкодер (Denoising Autoencoder), который искажает данные путем случайного обнуления некоторых входных значений или добавлением шумов. При вычислении функции потерь сравниваются выходные значения с исходными входными данными, а не с искаженными.
Применение Denoising Autoencoder:
- Извлечение признаков (Feature Extraction)
- Уменьшение размерности
12. Генеративно-состязательные сети (GAN)
Генеративно-состязательные сети (Generative Adversarial Network, GAN) учатся генерировать новые данные статистически неотличимых от исходных. Например, если мы обучим нашу модель GAN на фотографиях, то обученная модель сможет создавать новые фотографии, которые выглядят схоже с исходными. Или, например, генерировать картины в стиле Ван Гога или Пикассо.
Применение GAN:
- Генерация изображений и анимаций
- Редактирование лиц (т.н. эффект старения или нахождение похожего человека)
- Кибербезопасность
О том, как на практике применять глубокие нейронные сети для решения зада Data Science вы узнаете на нашем специализированном курсе «PYNN: Введение в Нейронные сети на Python» в лицензированном учебном центре обучения и повышения квалификации Data Scientist’ов и IT-специалистов в Москве.