
В предыдущей статье мы говорили о выделение признаков (feature extraction), как об одном из методов Transfer Learning. Сегодня изучим второй способ использования предварительно обученной модели в рамках feature extraction. Читайте в этой статье: как заморозить обученную модель VGG16 и соединить её с собственным классификатором в Python-фреймворке TensorFlow.
Использование предобученной сети для выделения признаков
Напомним, что в основе выделения признаков (feature extraction) лежит использование неизменной сверточной основы модели и собственного полносвязного слоя. В этой статье мы соединим архитектуру VGG16 со своим классификатором в Python-фреймворке TensorFlow для решения одной из задач компьютерного зрения (Computer Vision) — бинарной классификации.
Датасет с кошками и собаками
В качестве примера используем датасет с изображениями собак и кошек, доступный для скачивания. Также у нас имеется 3 директории для тренировочной, валидационной и тестовой выборки, каждая из которых имеет папки с собаками и кошками. Процесс разбиения датасета по папкам в Python обсуждался тут.
Далее, извлечём архитектуру VGG16, которая доступна в TensorFlow.Keras. Вот так выглядит скачивание архитектуры VGG16 в Python:
from tensorflow.keras.applications import VGG16
conv_base = VGG16(weights='imagenet', # Источник весов
include_top=False, # Не подключать полносвязный слой
input_shape=(150, 150, 3)) # Форма входных тензоров
Аргумент include_top определяет включение полносвязного слоя. ImageNet имеет 1000 классов, но в нашем случае только 2 класса, следовательно, можно обойтись одним нейроном (кошка/не кошка).
Создание модели в TensorFlow
VGG16 — обычная архитектура CNN, поэтому её легко подключить к другим слоям модели Sequential. Вот так выглядит добавление модели VGG16 к полносвязному слою в TensorFlow:
model = models.Sequential([
conv_base,
layers.Flatten(),
layers.Dense(256, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
Взглянем на то, как выглядит модель:
>>> model.summary() Model: "sequential_3" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= vgg16 (Functional) (None, 4, 4, 512) 14714688 _________________________________________________________________ flatten (Flatten) (None, 8192) 0 _________________________________________________________________ dense_6 (Dense) (None, 256) 2097408 _________________________________________________________________ dense_7 (Dense) (None, 1) 257 ================================================================= Total params: 16,812,353 Trainable params: 16,812,353 Non-trainable params: 0
Как видим, 14 миллионов параметров имеет архитектура VGG16, а классификатор добавил сверху еще 2 миллиона. Последний слой VGG16 выдает тензор с формой (образцы,4,4,512).
Замораживание модели
Очень важно для feature extraction заморозить сверточную основу, в противном случае будут изменяться её параметры. Сверточная основа CNN моделей обладает свойством инвариатности, т.е. не запоминает местоположения объектов, в отличие от полносвязных слоев, поэтому было бы лишним как-то её изменять, разрушив все прошлые представления.
Мы можем посмотреть сколько всего слоев, которые можно обучить до замораживание сети TensorFlow:
>>> print('Количество обучаемых весов до '
'замораживания сверточной основы:',
len(model.trainable_weights))
Количество обучаемых весов до замораживания сверточной основы: 30
Чтобы заморозить сверточную основу, нужно передать в атрибут trainable значение False. Вот так выглядит пример замораживание модели в Python-фреймворке TensorFlow:
>>> conv_base.trainable = False
>>> print('Количество обучаемых весов после '
'замораживания сверточной основы:',
len(model.trainable_weights))
Количество обучаемых весов после замораживания сверточной основы: 4
В итоге, после замораживание сверточной сети мы получили 4 весовых тензора: по два на каждый полносвязный слой, который имеет главную весовую матрицу и вектор смещений (bias).
Расширяем датасет с Data Augmentation
Данный способ, когда сверточная основа модели соединена с нашим классификатором, позволяет увеличивать объем данных с помощью Data Augmentation, о котором рассказывали тут. В TensorFlow для этой цели используется класс ImageDataGenerator. Вот так в Python выглядит подготовка датасета с изображениями:
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=.2,
height_shift_range=.2,
shear_range=.2,
zoom_range=.2,
horizontal_flip=True,
)
valid_datagen = ImageDataGenerator(rescale=1./255)
Затем нужно только указать директории с тренировочной и валидационной выборкой, которые содержат папки с изображениями кошек и собак:
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
valid_generator = test_datagen.flow_from_directory(
valid_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
Компиляция и обучение модели
Остается только скомпилировать и обучить модель TensorFlow. Но нужно учесть, что модель очень большая, поэтому лучше обучать её на GPU (можно воспользоваться Google Colab). Кроме того, поскольку используется генератор изображений, то необходимо указать аргумент steps_per_epoch, который определяет через сколько шагов перейти к следующей эпохе, иначе генерация будет происходить бесконечно. Пример на Python для обучения модели TensorFlow:
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
log_dir = "logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_steps=50,
validation_data=valid_generator,
callbacks=[tensorboard_callback])
Мы также инициализируем TensorBoard для визуализации. Чтобы посмотреть результаты в TensorBoard нужно лишь выполнить две строки:
%load_ext tensorboard %tensorboard --logdir logs
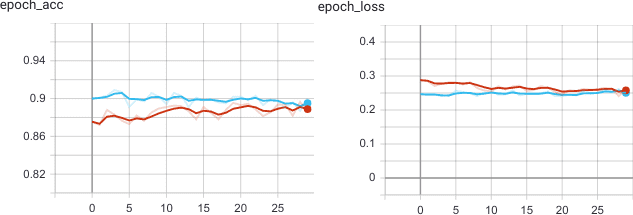
На 30 эпохах обучения графики TensorBoard показывают, что на валидационной выборке точность распознавания образов модели TensorFlow достигает 90%. Этот результат сопоставим с прошлым feature extraction, где мы сохраняли результат сверточной основы в массив NumPy (хотя там явно наблюдалось переобучение).
А о том, как применять метод feature extraction для трансферного обучения моделей машинного обучения на реальных примерах Data Science с использованием Python-фреймворка TensorFlow, вы узнаете на нашем специализированном курсе «VISI: Computer Vision» в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.

