Продолжаем говорить о сверточных нейронных сетях (CNN). Сегодня расскажем вам об одном из методов Transfer Learning — выделение признаков (feature extraction). Читайте в этой статье: использование предварительно обученной модели (VGG16) от TensorFlow для решения задачи классификации в Python, а также передача результатов сверточной основы в собственный классификатор.
Выделение признаков как один из методов Transfer Learning
Transfer Learning — это набирающий популярность метод обучения моделей машинного обучения для задач компьютерного зрения (Computer Vision), NLP и не только. В основе обучения лежит использование предобученных нейронных сетей. Кто-то, обладая большими вычислительными мощностями, сконструировал большую архитектуру нейронной сети, обучил в рамках решения своей задачи и опубликовал её на просторах Интернета. Мы, не имея в наличии множества GPU и больших данных (Big Data), используем предобученную модель для решения своей задачи. Нам не важно, что изначально обученная модель научена распознавать образы самолётов и автомобилей, мы можем использовать её для распознавания кошек и собак.
Сверточные нейронные сети (CNN) являются универсальным инструментом для работы с изображениями. Тем не менее предобученная модель без каких-либо изменений вряд ли покажет высокие результаты при решении текущей задачи (напр., распознавание животных). Поэтому мы дополняем её своими данными и получаем перепрофилированную модель, которая решает нашу задачу.
Transfer Learning предлагает два подхода использования предварительно обученных сетей:
- Выделение признаков (feature extraction)
- Дообучение (fine tuning)
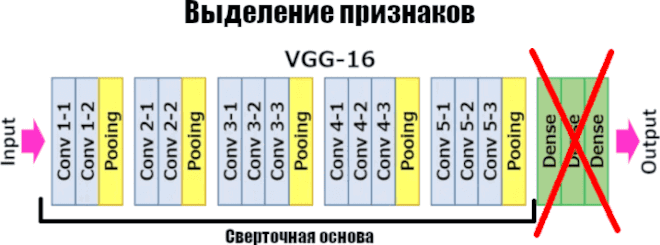
Мы рассмотрим feature extraction на примере простой архитектуры VGG16 с использованием Python-фреймворка TensorFlow [1]. Архитектура VGG16 обучена на данных из ImageNet, которая имеет больше миллиона изображений.
Выделение признаков для решения задачи классификации изображений
Выделение признаков заключается в использовании неизменной сверточной основы архитектуры и создании своего собственного классификатора. Как правило, в моделях CNN последний слой — полносвязный. В feature extraction мы отказываемся от этого слоя и реализуем свой, например через TensorFlow.
При создании своего полносвязного классификатора можно пойти несколькими способами:
- Пропустить входные данные через сверточную основу, получить выходные данные, сохранить их, а затем передать в свой классификатор. В TensorFlow для этого метода вызывается метод
predict, а затем полученный прогноз сохраняем в массив NumPy - Сразу же соединить сверточную основу с нашим классификатором. Этот способ разрешает использовать расширение данных Data Augmentation, о котором говорили тут, но он более затратный
В этой статье мы рассмотрим 1-й способ.
Датасет и извлечение сверточной основы
Мы используем набор данных с изображениями собак и кошек, доступный для скачивания. Разделим датасет на тренировочную, валидационную и тестовую выборки, каждая из которых имеет папки с собаками и кошками. Весь процесс разбиения можете посмотреть в прошлой статье.
Прежде всего скачаем архитектуру VGG16, которая доступна в TensorFlow. Вот так выглядит извлечение архитектуры VGG16 в Python:
from tensorflow.keras.applications import VGG16
conv_base = VGG16(weights='imagenet', # Источник весов
include_top=False, # Не подключать полносвязный слой
input_shape=(150, 150, 3)) # Форма входных тензоров
Аргумент include_top определяет включение полносвязного слоя. ImageNet имеет 1000 классов, но нам не нужно 1000 нейронов на выходе, для бинарной классификации можно обойтись одним. К тому же в основе feature extraction лежит избавление этот этого слоя.
Извлечение и сохранение признаков
Ниже Python-функция, которая извлекает признаки, выдаваемые сверточной основой архитектуры VGG16. Мы указали, что выходной признак должен иметь форму (образцы,4,4,512). Это связано с тем, что в VGG16 последний слой сверточной основы имеет именно такую форму (можно проверить вызовом model.summary) . Аргумент sample_count указывает количество передаваемых изображений.
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(rescale=1./255)
def extract_features(directory, sample_count, batch_size=20):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
for i, (inputs_batch, labels_batch) in enumerate(generator):
if i * batch_size >= sample_count:
# Генераторы могут находится в цикле до бесконечности,
# поэтому нужно прервать после передачи всех изображений
break
# Предказываем на основе сверточной основы VGG16:
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
return features, labels
Для каждого набора изображений (размера набора определяется batch_size) вызывается conv_base.predict для получения результата от сверточной основы. Этот результат мы сохраняем в features. Далее, остаётся только вызвать этот метод применительно к папкам с картинками:
train_features, train_labels = extract_features(train_dir, 2000) valid_features, valid_labels = extract_features(valid_dir, 1000) test_features, test_labels = extract_features(test_dir, 1000)
Поскольку полученные признаки имеют форму (образцы,4,4,512), то для передачи полносвязному классификатору требуется их преобразовать в форму (образцы,8192). Пример кода на Python для изменения формы массива NumPy:
train_features = np.reshape(train_features, (2000, 4 * 4 * 512)) valid_features = np.reshape(valid_features, (1000, 4 * 4 * 512)) test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
Создание собственного классификатора в TensorFlow
Ниже пример создания в TensorFlow полносвязного классификатора, который имеет на входе 256 нейронов и 1 на выходе (кошка/не кошка). Ещё мы добавили слой Dropout, чтобы избежать переобучения (overfitting). Также используем TensorBoard для визуализации полученных результатов. Код на Python для создания классификатора:
from tensorflow.keras import (
models, layers, optimizers)
from tensorflow.keras.callbacks import TensorBoard
from datetime import datetime
model = models.Sequential([
layers.Dense(256, activation='relu', input_dim=4 * 4 * 512),
layers.Dropout(0.5),
layers.Dense(1, activation='sigmoid')
])
log_dir = "logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = TensorBoard(log_dir=log_dir, histogram_freq=1)
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metrics=['acc'])
model.fit(train_features, train_labels,
epochs=30,
batch_size=20,
validation_data=(valid_features, valid_labels),
callbacks=[tensorboard_callback])
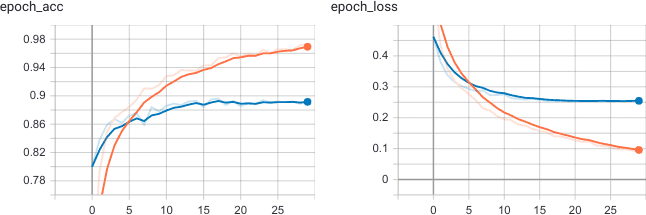
Как видим, на 30 эпохах обучения графики TensorBoard показывают, что на валидационной выборке точность достигает 90% для задачи распознавания образов кошек и собак в рамках компьютерного зрения на Python .
В следующей статье рассмотрим 2-й способ выделения признаков. Ещё больше подробностей о Transfer Learning и использовании предварительно обученных моделей на примерах реальных задач Computer Vision на языке Python, вы узнаете на нашем специализированном курсе «VISI: Computer Vision» в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.

