Мы уже рассказывали, как извлекать столбцы и строки главного объекта pandas – DataFrame, а также рассматривали, как строить графики. Сегодня будем получать заданные через условия данные так, как будто мы обращаемся к SQL-таблице. В Pandas это называется булевой индексацией.
Группировка Group By и агрегация данных в Pandas
Для примера возьмем датасет олимпийских игр с 1896 по 2016 года. Скачать его можно на сайте Kaggle — онлайн-площадке соревнований по машинному обучению. Сперва, импортируем библиотеку pandas и прочитаем датасет:
import pandas as pd
data = pd.read_csv('../athlete_events.csv')
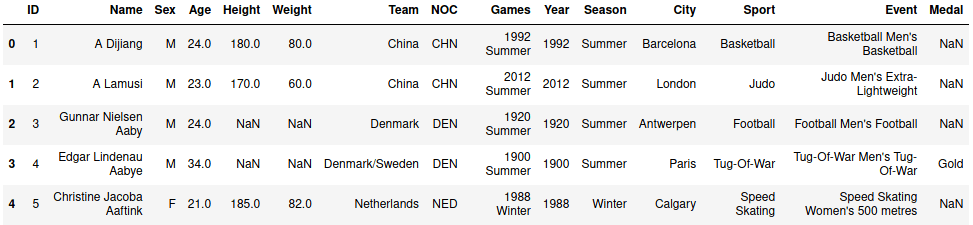
data.head()
Первые пять строк выглядят следующим образом:
В SQL-запросах есть команда GROUP BY, которая позволяет сгруппировать данные по атрибутам. В pandas такая команда называется groupby. Группировка по годам осуществляется следующим образом:
grouped_by_year = data.groupby('Year')
Тип возвращаемого объекта — DataFrameGroupBy:
>>> type(grouped_by_year) pandas.core.groupby.generic.DataFrameGroupBy
Агрегирование сгруппированных данных
C объектом DataFrameGroupBy можно выполнять разные функции агрегации такие как, нахождение минимального и максимального значения min и max, подсчет количества элементов count, статистические методы mean, std или var и т.д. Попробуем, например, посчитать количество записей каждой группы:
grouped_by_year.count()
Результат первых пяти годов выглядит следующим образом:
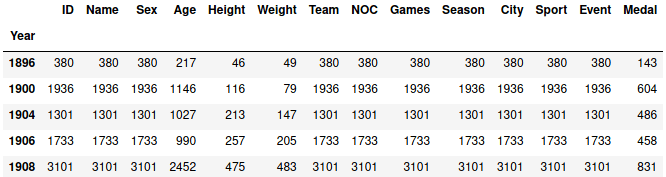
Как видим, подсчет происходит для каждого атрибута, причем в расчет не идут пустые Nan значения.
Для того чтобы получить минимальные/максимальные значения каждой группы, используется метод agg, который принимает в качестве аргумента словарь (dict). Этот словарь должен содержать ключ в виде необходимого атрибута и значение в виде функции агрегации. Например, определим минимальный возраст каждой группы:
grouped_by_year.agg({'Age': 'min'})
Первые пять строк отображаются как:
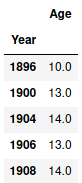
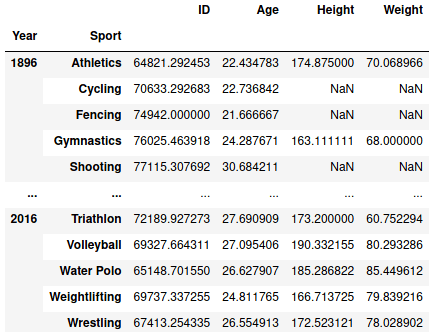
Вместо min можно использовать max, count, std. Также отметим, для группировки по нескольким атрибутам передается список. Попробуем сгруппировать по годам и виду спорта и найдем среднее:
data.groupby(['Year', 'Sport']).mean()
В результате имеем:
SQL-запросы с условием в Pandas
К DataFrame можно применять запросы с условием аналогично SQL-запросам WHEN и пр. Python-библиотека pandas имеет подобный синтаксис, называемый «булева индексация» [1]. В квадратных скобках указываются условия. Например, требуется определить возраст самого молодого мужчины, выступавшего в 1992 году. Можно написать следующее:
>>> data[(data['Year'] == 1992) & (data['Sex'] == 'M')]['Age'].min() 11.0
Здесь, в круглых скобках описывается условие для соответствующего атрибута DataFrame. Чтобы выполнить несколько условий используется оператор “И”, который записывается как “&”. Оператор “ИЛИ” имеет вид “|”. В результате выполнения условий возвращается объект DataFrame, поэтому к нему могут быть применены все его методы. В данном случае мы вызвали атрибут Age и определили минимальное значение min.
Также помимо знака равенства можно использовать знак сравнения:
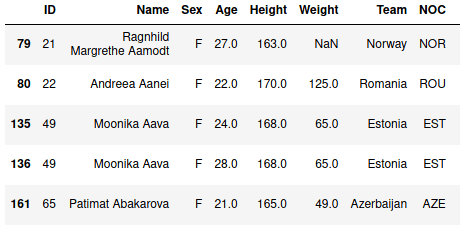
data[(data['Year'] > 2000) & (data['Sex'] == 'F')].head()
Результатом является пять строчек, содержащие данные о женщинах, которые выступали после 2000-го года:
Чтобы не перечислять каждый год по отдельности можно воспользоваться методом isin, который принимает список необходимых значений. Например, проверим количество уникальных записей 2002-го, 2006-го и 2008-го годов:
data[(data['Year'].isin([2008, 2006, 2002]))].nunique()
Также отметим, метод nunique отбрасывает дублирующиеся записи. Результат выглядит так:
ID 14788 Name 14762 Sex 2 Age 50 Height 82 Weight 147 Team 305 NOC 205 Games 3 Year 3 Season 2 City 3 Sport 49 Event 391 Medal 3 dtype: int64
Примеры кода выложены в github репозиторий. Как на практических примерах освоить Pandas и применять булеву индексацию, вы можете в наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.