Deep learning (глубокое обучение) – это часть семейства методов машинного обучения (Machine Learning), основанная на искусственных нейронных сетях, с обучением представлений. Многие виды архитектур глубокого обучения, такие как полносвязные нейронные сети, глубокие сети доверия, рекуррентные нейронные сети, сверточные нейронные сети применяются во многих прикладных областях.
Глубина глубокого обучения
Машинное обучение подразумевает нахождение значимого представления входных данных с использованием обратной связи. Рисунок ниже иллюстрирует это определение, где новое представление — это пространство, с разделенными белыми и черными точками.
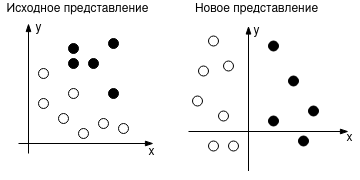
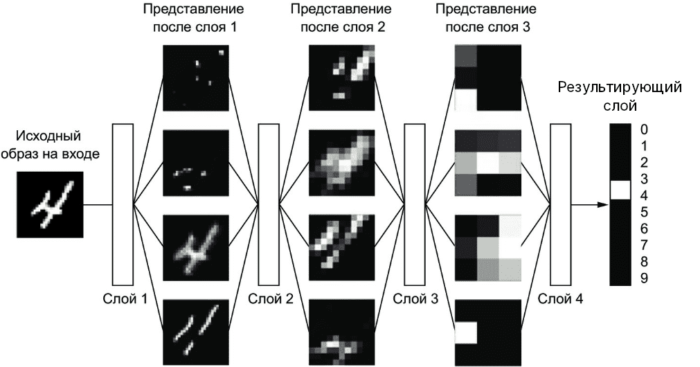
Глубокое обучение — один из методов машинного обучения и используется для нахождения нового представления данных. Но под глубиной глубокого обучения не имеется в виду глубокое понимание представлений. Йошуа Бенжио, один из пионеров искусственного интеллекта, в своей статье 2009 года высказал следующее: “Методы глубокого обучения нацелены на обучение иерархии признаков от высокого до низкого уровня. Автоматическое обучение признаков на разных уровнях абстракций позволяют системе изучать сложные функции, которые отображают входные данные в выходные, без какого-либо вмешательства человека” [1]. Иерархии, в данном случае, подразумевают слои нейронных сетей. Каждый параметр слоя определяет выявленный паттерн обучающей выборки, причем уровень абстракции последовательно снижается от слоя к слою. Рисунок ниже показывает, как изображение с цифрой представляется на каждом слое.
Обратное распространение ошибки: революция глубокого обучения
Множество ученых со всего мира внесли свой вклад в развитие искусственного интеллекта, среди которых особенно выделяются трое, названных “крестными отцами” глубокого обучения: Джеффри Хинтон, Ян Лекун, Йошуа Бенжио. Они поняли, что входной сигнал можно разложить на разные уровни или представления. Но для обучения этих самых представлений требуется особый метод. Им стал алгоритм обратного распространения ошибки.
Алгоритм обратного распространения ошибки (backpropagation) – это технология, которая вывела машинное обучение на новый уровень. Впервые он стал широко известен благодаря статье Хинтона в 1986 году [2]. Однако в то время алгоритм себя не зарекомендовал из-за причин:
- Размеченный датасет был слишком маленький,
- Компьютеры слишком медленные,
- Инициализация весов осуществлялась неверным способом,
- Подобранный тип функций активации был неверным.
В конце XX века были разработаны сверточные (convolutional) и рекурентные нейронные сети, включая LSTM (Долгая краткосрочная память, Long short-term memory). Но они не смогли тотчас же занять свою нишу из-за вышеперечисленных проблем. Например, на обучение сверточной сети для распознавания рукописных цифр уходило 3 дня [3], тогда как сегодня это занимает всего несколько минут, а то и меньше. А технология LSTM стала самым эффективным алгоритмом распознавания речи [4] только после 2013 года.
Терминология
Для обучения модели требуются данные. Чаще всего их разделяют на 3 категории:
- Тренировочный набор данных — данные, на которых обучается модель для нахождения новые представления.
- Тестовый набор данных — данные, на которых оценивают обученную модель.
- Валидационный набор данных — данные, на которых происходит оценка модели в процессе обучения.
В момент обучения может произойти утечка информации, то есть существует вероятность, что модель обучилась на валидационной выборке во время оценки. Для это и используется независимая тестовая выборка, которую модель не видела.
У модели есть свойства, которые задает человек перед обучением. Эти свойства называются гиперпараметрами, к ним относятся:
- Количество слоев
- Количество нейронов в каждом слое
- Количество эпох обучения
- Размер пакетов обучения
- Функции активации
- Функции потерь
- Оптимизаторы (алгоритмы оптимизации также имеют свои параметры)
Параметры модели настраиваются в процессе обучения не человеком, а алгоритмом обратного распространения ошибки, к ним относятся:
- Веса (weights)
- Смещения(bias)
Принцип действия глубокого обучения
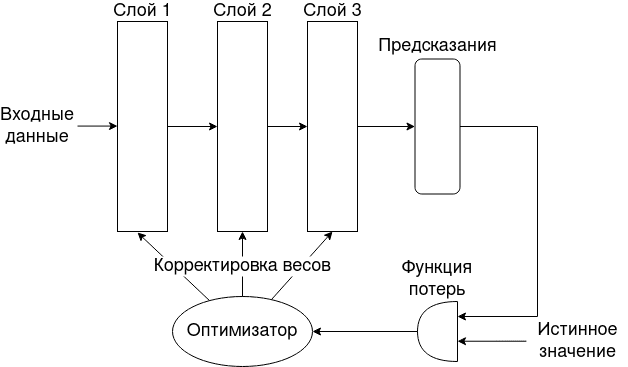
Глубокое обучение, представляя входные данные в каждом слое, выдает предсказание. Оценкой результата занимается функция потерь, которая вычисляет расстояние между предсказанным значением и истинным. Тогда задачей обучения является нахождение параметров модели, при которых значение функции потерь минимально.
Процесс обучения можно подразделить на две стадии:
- прямой проход (feed forward)
- обратный проход (backward)
В прямом проходе осуществляется движение входного сигнала через все промежуточные слои до выходного слоя. Слои обладают функцией активацией, которая преобразует сигналы в нелинейную функцию, например, функция активации softmax выдает вероятность принадлежности классу, поэтому используется на последнем выходном слое.
Обратный проход подразумевает изменение весов в соответствие с выданными результатами функции потерь от выходного слоя через промежуточные до входного. Корректировка весов осуществляется через оптимизатор, который реализует алгоритм обратного распространения ошибки.
Сферы применения: где используется Deep Learning
Глубокое обучение может быть применено практически в любой области, где содержится большой набор данных (Big Data), например:
- Рекомендательные системы используются в интернет-магазинах, социальных сетях, чат-ботах.
- Машинные переводы с одного языка на другой.
- Преобразование изображений, например, перевод черно-белой фотографии в цветную.
- Компьютерное зрение для распознавания объектов.
- Управление беспилотными автомобилями.
- Генерация текстов, например, написание стихов.
Читайте также:
- TensorFlow vs PyTorch
- Краткий обзор TensorFlow
- Краткий обзор PyTorch
- 3 метода детектирования объектов c Deep learning: R-CNN, FastR-CNN и Faster R-CNN
Источники: