В данной статье рассмотрим принцип обучения моделей машинного обучения, а так же реализуем итеративный цикл обучения линейной регрессии методом стохастического градиентного спуска.
Оптимизация в машинном обучении
Машинное обучение является важным инструментом в современной аналитике данных и искусственном интеллекте. Основным принципом работы методов машинного обучения является построение модели, которая может автоматически обучаться на основе предоставленных данных и в последующем делать прогнозы на основе этого обучения. Неотъемлемым компонентом цикла жизни модели является её обучение, а значит оптимизация её параметров.
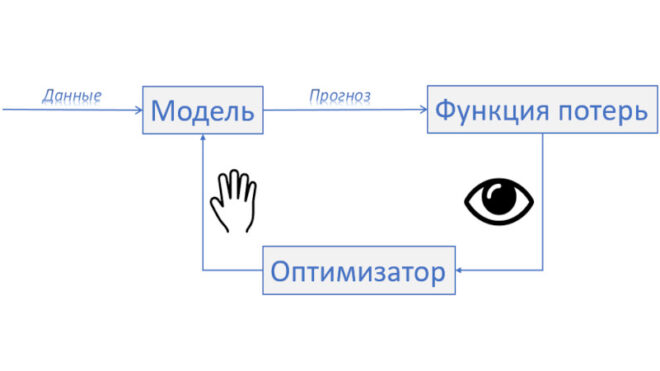
Каждая модель имеет свою уникальную логику работы и принятия решения, но процесс обучения моделей машинного обучения можно свести к трем основным блокам. Первый это непосредственно модель, её логика по которой она будет принимать решение и параметры модели которые нам нужно подобрать так, чтобы модель качественно описывала выборку. Далее я буду называть это телом модели. Второй блок это непосредственно метрика по которой мы оцениваем модель – функция потерь. Третий блок это алгоритм подбирающий параметры тела модели опираясь на функцию потерь, оптимизатор.
Тело модели является функцией, которая определяет взаимосвязь между входными данными и выходными данными. Оно может быть линейным или нелинейным, и его сложность зависит от сложности задачи, которую необходимо решить.
Функция потерь используется для оценки качества модели. Она показывает, насколько точно модель предсказывает выходные данные на основе входных данных. Чем меньше значение функции потерь, тем лучше модель подходит для данных. При обучении модели следует с умом подходить к её выбору.
Оптимизатор — это алгоритм, который используется для минимизации функции потерь. Он определяет, какие изменения необходимо внести в тело модели, чтобы уменьшить значение функции потерь. Различные оптимизаторы имеют различные свойства и могут быть использованы в зависимости от сложности модели и задачи. В данном случае автор имеет ввиду под оптимизатором любой алгоритм поиска минимума функции ошибки, даже если подбор осуществляется аналитически.
В целом, эти три элемента — тело модели, функция потерь и оптимизатор — являются ключевыми компонентами в работе методов машинного обучения. Они взаимодействуют друг с другом, чтобы позволить модели автоматически обучаться и делать прогнозы на основе предоставленных данных.
В процессе обучения, модель получает входные данные и использует их для предсказания выходных данных. Затем, результаты предсказания сравниваются с реальными данными, используя функцию потерь. На основе этого сравнения функция потерь вычисляет ошибку, которую необходимо минимизировать. Оптимизатор использует эту информацию об ошибке, чтобы определить, какие изменения необходимо внести в веса и параметры тела модели. Таким образом, оптимизатор производит изменения в модели, пока функция потерь не достигнет минимума.
После завершения обучения, модель может использоваться для предсказания новых данных, используя только тело модели, а значит параметры, которые были оптимизированы во время обучения.
Если проводить аналогии с обучением людей, то тело модели – это ученик, оптимизатор – это учитель, а функция потерь – это контрольная.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
16 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000 руб.
Реализация цикла обучения в Python
Для понимания выше описанной концепции реализуем обучение простейшей модели линейной регрессии используя алгоритм стохастического градиентного спуска. Для этого используем стандартный датасет scikit-learn о диабетиках. Цель модели в данном случае количественно предсказать прогрессию заболевания через год после исходного уровня. Для реализации цикла обучения воспользуемся библиотекой глубокого обучения PyTorch, так как она умеет автоматически рассчитывать градиенты. Для начала импортируем всё что над для этого понадобится:
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_diabetes from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import train_test_split
Первым делом получим данные и нормируем их, так как линейная регрессия очень чувствительна к нормировке:
# получаем датасет из библиотеки sklearn diabetes = load_diabetes() scaler = MinMaxScaler() inputs = scaler.fit_transform(diabetes.data) targets = diabetes.target X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=0.3, random_state=42) X_train, X_test = torch.from_numpy(X_train).float(), torch.from_numpy(X_test).float() y_train, y_test = torch.from_numpy(y_train).float().view(-1, 1), torch.from_numpy(y_test).float().view(-1, 1)
Далее реализуем линейную регрессию используя PyTorch:
class LinearRegression(nn.Module): def __init__(self, input_size, output_size): super().__init__() self.weights = nn.Parameter(torch.randn(input_size, output_size)) self.bias = nn.Parameter(torch.randn(output_size)) def forward(self, x): return x @ self.weights + self.bias
Далее инициализируем функцию потерь MSE, оптимизатор SGD, и непосредственно модель:
# Инициализируем модель input_size = X_train.shape[1] output_size = 1 model = LinearRegression(input_size, output_size) # Инициализируем фуункцию потерь и оптимизатор criterion = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr=0.1)
Далее напишем непосредственно цикл обучения на 50000 эпох:
# Запускаем обучение
num_epochs = 50000
for epoch in range(num_epochs):
# Forward pass
outputs = model(X_train) # Получаем предсказания
loss = criterion(outputs, y_train) # Обсчитываем функцию потерь
# Выполняем оптимизацию параметров модели
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Print the loss
if (epoch+1) % 500 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
Оценим качество итоговой модели:
print(f'MSE модели на обучающей выборке {criterion(model(X_train), y_train)}')
print(f'MSE модели на тестовой выборке {criterion(model(X_test), y_test)}')
Out:
MSE модели на обучающей выборке 2924.220458984375
MSE модели на тестовой выборке 2821.435302734375
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
16 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000 руб.
Оптимизация является неотъемлемой частью машинного обучения и играет ключевую роль в формировании качественной модели. Определение целевой функции и поиск ее минимума позволяют нам находить оптимальные параметры модели, которые в свою очередь повышают ее точность и способность к генерализации. Оптимизация является одним из основных инструментов в области Data Science. Для дальнейшего изучения этой темы, а также для получения знаний о более современных методах и инструментах, приглашаем вас посетить наш лицензированный учебный центр в Москве, специализирующийся на повышении квалификации ИТ-специалистов, где вы сможете принять участие в практических курсах «Машинное обучение на Python«.

