В этой статье мы проанализируем разницу между NumPy и Pandas – 2-мя популярными Python-библиотеками, которые часто используются в Data Science и Machine Learning: разберем их достоинства и недостатки, а также особенности практического использования.
NumPy — нам важна производительность
NumPy расшифровывается как «Numeric Python», что можно перевести как «Числовой Python». Данная библиотека предоставляет возможности работы с многомерными массивами. В ее основе лежит класс ndarray – многомерный контейнер элементов одного типа данных и размера. Объекты этого класса занимают меньше памяти, а операции над ними производятся быстрее, чем с обычными списками Python. C чем это связано?
Меньший расход памяти обеспечивается за счет всегда определенно заданного размера, так как все элементы одного типа, например, int32 или float32. Быстрота объясняется избеганием питоновских циклов. NumPy использует низкоуровневый язык программирования С, а многомерный объект ndarray разворачивается в одномерный массив С.
Список (list) в Python «под капотом» содержит массив указателей на объекты. Поэтому извлечение элементов списка подразумевает обращение к объекту и проверку типов. Проведем бытовую аналогию: представьте, что вам нужно перетащить кучу коробок, которые находятся в 20 метрах от вас. При этом вам нужно заглядывать в каждую коробку, чтобы проверить ее содержимое. С точки зрения языка С это бы выглядело так: коробки находятся прямо перед вами, заглядывать внутрь не нужно, к тому же вы всегда знаете точное их количество и массу каждой коробки. Вот поэтому массивы NumPy так эффективны, но накладывают определенные ограничения.
Pandas — удобство использования превыше всего
«Panel Data», сокращено Pandas, на русский язык можно перевести как «Панельные данные». Данный термин в эконометрии используется для набора данных, включающих многократные наблюдения за одними и теми же лицами.
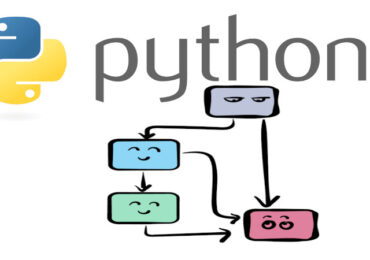
В основе Pandas лежит класс DataFrame, предоставляющий возможности работы с двумерными массивами неоднотипных данных. Объект DataFrame составлен из объектов Series — одномерных массивов NumPy ndarray, объединенных под одним названием. Поэтому в DataFrame каждый столбец может иметь свой тип данных. На рисунке схематично показано архитектура DataFrame:

В отличие от NumPy, библиотека Pandas не требует знаний линейной алгебра или умений работать с многомерными массивами (тензорами), которые мы разбирали в этой статье. DataFrame можно представить как таблицу, где каждая строка представляет единичное наблюдение. А со строками и столбцами удобно работать. Python-библиотека Pandas поддерживает такие же операции, как и NumPy: индексация массивов, статистические исследования, работу с пустыми (Nan) значениями, изменение формы массивов, извлечение отдельных элементов, конкатенацию. Помимо этого, Pandas также позволяет:
- чтение и запись данных, например, csv или excel таблица;
- группировку данных;
- средства визуализации данных;
- работу с датами;
- работу со строковыми значениями и т.д.
Numpy и Pandas — лучшие друзья Data Scienctist’а
На практике при решении задач Data Science и Machine Learning приходится работать с обеими рассмотренными библиотеками, т.к. они позволяют быстро и просто обрабатывать большие объемы данных. Даже на онлайн-площадке соревнований по машинному обучению Kaggle [1] обычно первые строчки кода программистов начинаются с import pandas as pd, а ниже можно увидеть операцию чтения датасета — pd.read_csv(...). Действительно, в первую очередь необходимо взглянуть на датасет, проанализировать его, построить необходимые графики. Здесь и нужен Pandas.
NumPy, в свою очередь, используется практически в везде, включая другие библиотеки Python, связанные с Data Science и Machine Learning. Например, уже упомянутый Pandas, Seaborn, Statsmodel, в анализе сигналов — Scipy, PyWavelets, в обработке изображений — Scikit-learn и OpenCV, в симуляции моделей — PyDSTool, в глубоком обучении — Keras [2, 3]. Таким образом, эти простые библиотеки являются фундаментом Data Science в Python.
В следующей статье мы продолжим разговор о библиотеках машинного обучения и рассмотрим четыре самых востребованных из них по версии Kaggle. А практические навыки работы с NumPy и Pandas вы получите на курсах по Python в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.