Графовые нейронные сети (Graph Neural Net, GNN) — набирающие популярность архитектуры в Machine Learning и Deep Learning. Одна из причин их популярности состоит в том, что данные и связи между ними могут быть представлены в виде графа. В этой статье мы научимся строить графовые нейронные сети с нуля.
Графовые нейронные сети что это
Графовые нейронные сети применяются для графовых данных. Например, в задаче классификации GNN должна классифицировать узлы графа: сами узлы должны представлять собой метку некоторого класса. Поэтому данные, которые представляют собой графовую структуру (например, связи в социальных сетях), могут быть использованы для обучения GNN.
Рассмотрим пример графовых нейронных сетей с использованием TensorFlow.
Пример графовых данных
Мы будет использовать специальный датасет Cora. Этот датасет состоит из 2708 статей о Machine Learning, каждая из которых разделена на одну из 7 тематик и имеет ссылки (цитирования) на другие статьи. Статья имеет бинарный 1433-мерный вектор, где 0/1 представляет имеет ли он слово из заданного словаря.
В первую очередь скачаем датасет:
import os
from tensorflow import keras
url = "https://linqs-data.soe.ucsc.edu/public/lbc/cora.tgz"
zip_file = keras.utils.get_file(
fname="cora.tgz",
origin=url,
extract=True
)
data_dir = os.path.join(os.path.dirname(zip_file), "cora")
Датасет снабжен двумя файлами:
- `cora.cities`, который включает цитирования; - `cora.content`, который включает сами статьи.
Преобразуем данные с цитированием в DataFrame:
import pandas as pd
citations_data = pd.read_csv(
os.path.join(data_dir, "cora.cites"),
sep="\t",
header=None,
names=["target", "source"],
)
Он имеет два атрибута: source (кто цитирует) и target (кого цитирует).
Теперь представим содержимое файла core.content в виде мешка слов, о котором говорили тут:
column_names = ["paper_id"]
+ [f"term_{idx}" for idx in range(1433)]
+ ["subject"]
papers_data = pd.read_csv(
os.path.join(data_dir, "cora.content"),
sep="\t",
header=None,
names=column_names,
)
Рассмотрим, что получилось:
print("Papers shape:", papers_data.shape)
papers_data.head()
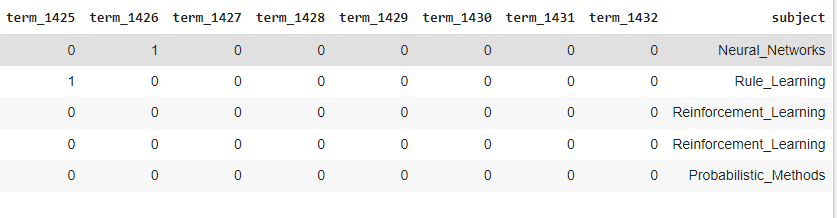
Как видим, в итоге получается таблица 2708×1435, где последним столбцом является тематика статьи. Теперь снабдим каждую статью ссылками на цитирование:
class_values = sorted(papers_data["subject"].unique())
class_idc = {name: id for id, name in enumerate(class_values)}
paper_idc = {name: idx for idx, name in enumerate(sorted(papers_data["paper_id"].unique()))}
papers_data["paper_id"] = papers_data["paper_id"].apply(lambda name: paper_idc[name])
citations_data["source"] = citations_data["source"].apply(lambda name: paper_idc[name])
citations_data["target"] = citations_data["target"].apply(lambda name: paper_idc[name])
papers_data["subject"] = papers_data["subject"].apply(lambda value: class_idc[value
Визуализация данных
Просто иметь данные не очень удобно. Лучше всего построить граф на основе полученных данных. Это можно сделать с помощью библиотеки networkx:
import networkx as nx import matplotlib.pyplot as plt plt.figure(figsize=(10, 10)) colors = papers_data["subject"].tolist() cora_graph = nx.from_pandas_edgelist(citations_data.sample(n=1500)) subjects = list(papers_data[papers_data["paper_id"].isin(list(cora_graph.nodes))]["subject"]) nx.draw_spring(cora_graph, node_size=15, node_color=subjects)

Узлом данного графа является статья, а соединение — цитированием. Цвет обозначает тематику статьи. Однако мы еще не преобразовали данные в виде графа.
Приводим данные к графовому виду
GNN требует именно графовых данных. Этим мы и займемся: преобразуем данные в виде графа. Базовый граф состоит из следующих сущностей:
- Признаки узла — это количество узлов и количество признаков в массиве. Например, в данном датасете признаками является бинарный вектор для каждой статьи.
- Ребра графа — это разреженная матрица соединений узлов. В нашем датасете это цитирования.
- Веса ребер — количество ссылающихся узла. Ведь если на узел ссылается много других узлов, то и узлы, на которые ссылается он тоже авторитетны.
Итак, исходя из этих определений построим граф данных. Признаками является вектор из слов:
import tensorflow as tf
feature_names = set(papers.columns) - {"paper_id", "subject"}
print(feature_names)
"""
{'term_331', 'term_781', 'term_123', ...}
"""
Узлами является цитирующий (source) и цитируемый (target) объект:
edges = citations_data[["source", "target"]].to_numpy().T print(edges.shape) """ (2, 5429) """
Теперь на этой основе построим признаки узла, где для каждой статьи дадим собственный мешок слов:
node_features = tf.cast(
papers_data.sort_values("paper_id")[feature_names].to_numpy(),
dtype=tf.dtypes.float32
)
print(node_features.shape)
"""
(2708, 1433)
"""
И, наконец, веса ребер:
edge_weights = tf.ones(shape=edges.shape[1]) print(edge_weights.shape) """ (5429,) """
Теперь мы готовые построить граф данных с использованием кортежа:
graph_info = (node_features, edges, edge_weights)
Реализация графовой нейронной сети
Код курса
GRAF
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Первое что нужно сделать — это построить графовый слой. Что нам нужно для этого сделать?
- Подготовить входные узлы с использованием нейронной сети прямого распространения.
- Обеспечить передачу сообщения (отклика) от узла до его соседей с учетом весов. В терминах математики это означает использование сочетаний инвариантного пулинга (using permutation invariant pooling).
- Создать новые состояния представления узлов. Здесь мы комбинируем представления узлов и их сообщений. Например, если этой комбинацией является GRU (Gated recurrent unit, Управляемый рекуррентный блок), тогда представление узлов и сообщений могут быть соединены вместе для создания последовательности, которая затем подается в GRU.
Для всего этого был создан с помощью Keras графовый сверточный слой, который состоит из подготовительных, комбинирующих и обновляющих функций.
Применение классификатора на основе графовой нейронной сети
После создания GNN сделаем классификатор. Он будет выполнять следующее:
- предобработку признаков узлов для генерация их представления;
- применение разработанного графового слоя;
- последующую обработку представления узлов для генерации окончательного представления;
- применение слоя с softmax для создания предсказаний.
Код с графовым слоем и классификатором можете посмотреть здесь.
Обучение модели
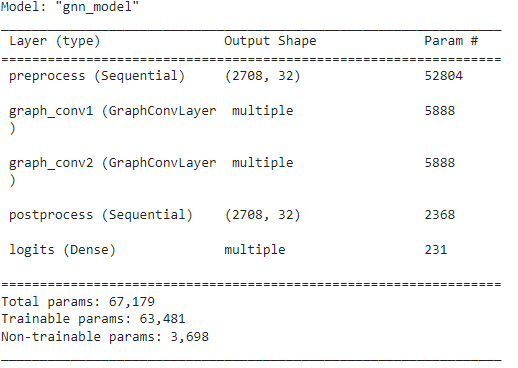
Инициализируем модель:
hidden_units = [32, 32]
learning_rate = 0.01
dropout_rate = 0.5
num_epochs = 300
batch_size = 256
gnn_model = GNNNodeClassifier(
graph_info=graph_info,
num_classes=num_classes,
hidden_units=hidden_units,
dropout_rate=dropout_rate,
name="gnn_model",
)
gnn_model.summary()
Вынесем тренировочные данные:
x_train = train_data.paper_id.to_numpy() y_train = train_data["subject"]
А также создадим функцию, которая будет компилировать и обучать модель:
def run_experiment(model, x_train, y_train):
model.compile(
optimizer=keras.optimizers.Adam(learning_rate),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)
early_stopping = keras.callbacks.EarlyStopping(
monitor="val_acc", patience=50, restore_best_weights=True
)
history = model.fit(
x=x_train,
y=y_train,
epochs=num_epochs,
batch_size=batch_size,
validation_split=0.15,
callbacks=[early_stopping],
)
return history
history = run_experiment(gnn_model, x_train, y_train)
Визуализация результатов
Визуализация результатов
С помощью библиотеки matplotlib построим график изменения точности с каждой эпохой:
fig, ax2 = plt.subplots(1, figsize=(15, 5))
ax2.plot(history.history["acc"])
ax2.plot(history.history["val_acc"])
ax2.legend(["train", "test"], loc="upper right")
ax2.set_xlabel("Epochs")
ax2.set_ylabel("Accuracy")
plt.show()
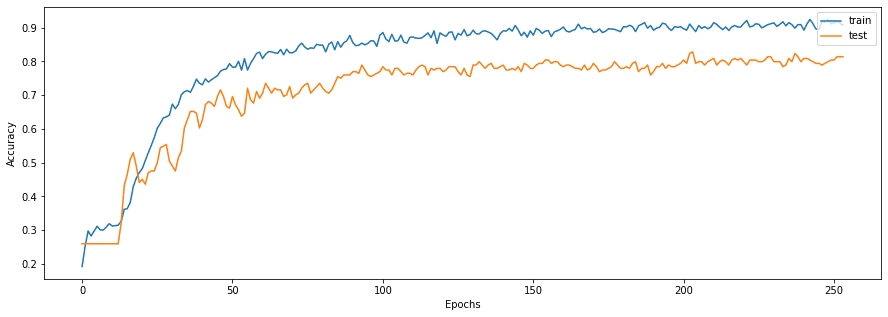
Как видим, что модель обучилась и имеет точность 90% на тренировочных и 80% на тестовых данных.
При построение графовой нейронной сети лишь требуется подготовить данные и написать соответствующую архитектуру.
Еще больше о графовых нейронных сетях вы узнаете на специализированном курсе «Графовые алгоритмы. Бизнес-приложения» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.