В прошлый раз мы разобрались с основными принципами работы тензоров в numpy, о важности представления данных для Machine Learning. В этой статье поговорим об индексации тензоров — научимся извлекать необходимые нам элементы. Мы не будем говорить о тензоре 1-го ранга, так как это всего лишь число. Как обычно, перед началом импортируем библиотеку numpy c обращением в виде np:
import numpy as np
Индексация тензоров 1-го ранга
Тензора 1-го ранга — это вектор или обычный одномерный массив:
>>> a = np.array([1, 2, 3, 4, 5])
Чтобы извлечь элемент, указываем индекс элемента (индексация начинается с нуля) в квадратных скобках. Например, извлекаем 2-й элемент:
>>> a[2] 3
Чтобы извлечь подмассив нужно указать через двоеточие:
- start — индекс, с которого начать срез массива,
- stop — индекс, на котором закончить срез массива (не включительно),
- step — шаг, через который переступать при срезе массива.
Например, создаем подмассив с индексами 1 по 4:
>>> a[1:4] array([2, 3, 4])
Шаг в этом примере не указан.
Векторы используются в классических алгоритмах машинного обучения, например, в методе опорных векторов
Индексация тензоров 2-го ранга
Тензор второго ранга — это матрица или двумерный массив. В Питоне он может быть записан следующим образом:
>>> a = np.array([[1, 2, 13, 14], [5, 6, 17, 18], [9, 3, 11, 12]]) >>> a array([[ 1, 2, 13, 14], [ 5, 6, 17, 18], [ 9, 3, 11, 12]])
У матрицы имеются две оси: строки и столбцы. В качестве примера, на рисунке обозначены индексы: i — строки, j — столбцы:
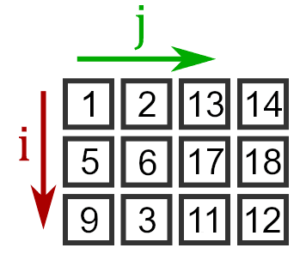
Для обращения к осям используется запятая.
Чтобы извлечь элемент, указываем через запятую индекс строки, затем индекс столбца:
>>> a[2, 1] 3
Чтобы извлечь строку, достаточно указать индекс в квадратных скобках:
>>> a[1] array([ 5, 6, 17, 18])
Чтобы извлечь столбец, нужно явно указать номера строк. Например, для извлечения всех строк необходимого столбца используется двоеточие:
>>> a[:, 2] array([13, 17, 11])
Кроме того, можно получить элементы, стоящие на определенных строках и столбцах. Например, извлечем элементы, лежащие на строке с индексом 1 и на столбцах от 1 до 3:
>>> a[1, 1:3] array([ 6, 17])
Индексация тензоров 3-го ранга
Тензор третьего ранга — это массив матриц. В Python записывается как:
>>> a = np.array([[[10, 11, 12], [14, 15, 16], [18, 19, 20]], [[22, 23, 24], [26, 27, 28], [30, 31, 32]], [[34, 35, 36], [38, 39, 40], [42, 43, 44]]]) >>> a array([[[10, 11, 12], [14, 15, 16], [18, 19, 20]], [[22, 23, 24], [26, 27, 28], [30, 31, 32]], [[34, 35, 36], [38, 39, 40], [42, 43, 44]]])
У такого тензора 3 оси: матрица, строка, столбец. На рисунке обозначены индексы: i — матрицы, j — строки, k — столбцы:
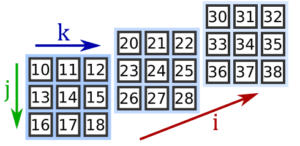
Чтобы извлечь элемент, указываем через запятую индекс матрицы, строки, затем столбца:
>>> a[1, 2, 0] 30
Чтобы извлечь матрицу, достаточно указать индекс в квадратных скобках:
>>> a[2] array([[34, 35, 36], [38, 39, 40], [42, 43, 44]])
Чтобы извлечь строку матрицы, указывается через запятую индекс матрицы, затем строки:
>>> a[2, 1] array([38, 39, 40])
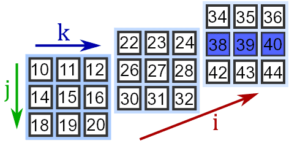
Чтобы извлечь столбец матрицы, указывается номер матрицы, выбираются все строки матрица, затем номер столбца:
>>> a[0, :, 2] array([12, 16, 20])
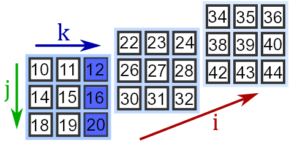
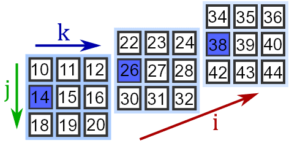
Извлечение элементов всех матриц происходит через двоеточие. Например, получим элементы матриц, стоящих на 1-й строке, 0-м столбце:
a[:, 1, 0] array([14, 26, 38])
Тензор третьего ранга можно использовать как представление черно-белых изображений для Machine Learning, где каждая матрица будет представлять одно изображение с элементами, равные пикселям.
Посмотреть исходный код можно в github репозитории. В следующей статье мы сравним библиотеки Pandas и NumPy: в чем различие, в каких случаях нужно использовать их для Data Science. C манипулированиями тензорами в NumPy, представлениями данных для Machine Learning вы познакомитесь на практических курсах по Python в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.