Задача регрессии возникает, когда требуется предсказать цену, температура, пульс, время, давление или другое численный показатель. Это пример контролируемого (supervised) машинного обучения, когда на основе истории предыдущих данных мы получаем предсказание. В этой статье обсудим, как можно спрогнозировать будущее, решая задачу линейной регрессии на Python.
Постановка задачи и исходный датасет
Продолжим работу с датасетом нью-йоркских апартаментов (отелей), доступных для проживания на некоторое время. Для дальнейшего анализа возьмем район Бруклин:
import pandas as pd
data = pd.read_csv('../AB_NYC_2019.csv')
data = data[data['neighbourhood_group'] == 'Brooklyn']
На этом наборе данных будем прогнозировать цены, по которым можно арендовать отдельные аппартаменты.
Линейная регрессия с одной независимой переменной
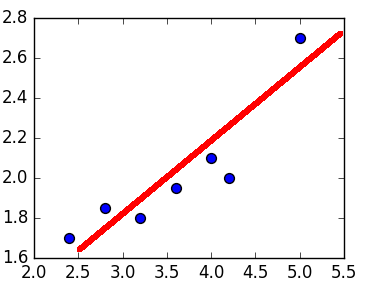
Графически линейная регрессия с одной независимой выглядит как прямая. Она решает задачу регрессии нахождением прямой, которая наилучшим образом соответствует точкам наблюдений. Следующий рисунок иллюстрирует вышесказанное:
Модель линейной регрессии может быть задана следующим образом:
![\[ y = ax + b \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-72c89b490295c32f121a3e4ad8984e7a_l3.png "Rendered by QuickLaTeX.com")
Следовательно, для решения задачи регрессии требуется найти коэффициенты  (коэффициент наклона) и
(коэффициент наклона) и  (точка пересечения линии с осью ординат). Не вдаваясь в подробности, их можно выразить так:
(точка пересечения линии с осью ординат). Не вдаваясь в подробности, их можно выразить так:
![\[ a=\frac{\sum(x-\bar{x})(y-\bar{y})}{\sum(x-\bar{x})^2} \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-ce7eea517462090da3e4aa2d9f5be9f5_l3.png "Rendered by QuickLaTeX.com")
![\[ b=\bar{y}-ay \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-426594f6814115dc99c1f34633c18d84_l3.png "Rendered by QuickLaTeX.com")
Найдем коэффициенты в Python, написав следующие функции:
def calculate_slope(x, y):
mx = x - x.mean()
my = y - y.mean()
return sum(mx * my) / sum(mx**2)
def get_params(x, y):
a = calculate_slope(x, y)
b = y.mean() - a * x.mean()
return a, b
Стоит заметить, функция calculate_slope сначала находит произведение двух массивов, только потом суммирует результат этого произведения.
В нашем случае выберем в качестве независимой переменной  — количество отзывов
— количество отзывов number_of_reviews, a зависимой переменной  , которую требуется предсказать, будет цена
, которую требуется предсказать, будет цена price. Кроме того, чтобы избежать излишней волатильности цены, мы ее прологарифмируем, как это объяснялось в прошлый раз. Посмотрим на полученные коэффициенты:
import numpy as np d = data[data.price > 0] x = d.number_of_reviews y = np.log(d.price) a, b = get_params(x, y)
В итоге получили:
>>> a -0.04213862786693919 >>> b 125.40308200933784
Мы отфильтровали нулевые значения цены, так как логарифма от нуля не существует. Таким образом, в Python линейная регрессия, исходя из полученных коэффициентов будет задаваться как:
lin_reg = a*x + b
Построим график в Python-библиотеке matplotlib, на котором будет видна полученная линейная регрессия и истинные значения цены. О том, как строить графики, мы рассказывали тут. Для этого воспользуемся функциями scatter и plot:
import matplotlib.pyplot as plt
plt.xlabel('Количество отзывов')
plt.ylabel('Цена в логарифмическом масштабе')
plt.scatter(x, y)
plt.plot(x, lin_reg, color='red')
В результате получили график:
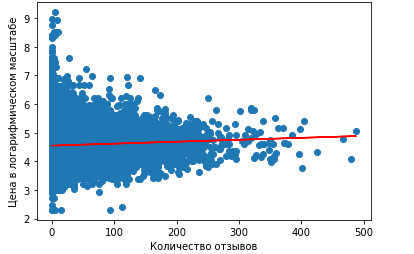
Как можно заметить, линейная регрессия с одной независимой переменной показывает неудачные результаты, так как является практически параллельной оси абсцисс. Поэтому предсказание будет одним и тем же, примерно равным 4.6. При переводе обратно в нормальный масштаб равняется $100.
Линейная регрессия в библиотеках statsmodel и seaborn
Чтобы получить линейную регрессию, Data Scientist, который работает с Python, может воспользоваться готовыми библиотеками, а не писать собственное решение. Например, отлично подойдет библиотека Statsmodel, о которой мы уже говорили здесь. Она позволит получить линейную регрессию очень быстро:
import statsmodels.formula.api as smf
model = smf.ols('price ~ number_of_reviews', data=data)
res = model.fit()
res.summary()
Метод summary выдает резюме после вычислений линейной регрессии по методу наименьших квадратов. Но нас интересуют коэффициенты и , которые в данном случае равны:

Как видим, intercept — это , number_of reviews, — это , что соответствуют прошлым вычислениям.
Помимо Statsmodel, можно воспользоваться библиотекой Seaborn, которая также часто применяется в задачах Machine Learning и других методах Data Science. Она имеет функцию regplot, которая сразу построит соответствующую прямую:
import seaborn as sns sns.regplot(x, y)
Линейная регрессия с несколькими переменными в Scikit-learn
В действительности ML-модели редко обучаются только на одном признаке, что подтверждают построенные графики. Поэтому уравнение для линейной регрессии можно обобщить до  переменных (признаков):
переменных (признаков):
![\[ y = ax_1 + ax_2 \dots + \dots + ax_n \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-a76fa97ac86f43f49f95dac412a3cbb6_l3.png "Rendered by QuickLaTeX.com")
где задача сводится к нахождению коэффициентов. Не вдаваясь в подробности их нахождения, отметим, что Python-библиотека Scikit-learn предоставляет для этого уже готовый интерфейс.
Рассмотрим пример в Python. Выберем в качестве независимых переменных признаки: number_of_reviews, reviews_per_month, calculated_host_listings_count. Атрибут reviews_per_month имеет Nan-значения, поэтому в дальнейшем заполним их нулями. К тому же, мы отфильтровали те данные, которые имеют нулевую цену:
d = data[data.price > 0]
d['reviews_per_month'].fillna(0, inplace=True)
x = d.loc[:, ('reviews_per_month',
'calculated_host_listings_count',
'number_of_reviews')]
y = d.loc[:, 'price']
Здесь используется метод loc, который, согласно документации, быстрее и производительнее явного вызова столбцов [1]. Нам также требуется разбить полученные данные на тренировочную и тестовую выборки, чтобы на одних данных обучить модель, а на других – проверить ее корректность. В Scikit-learn имеется функция train_test_split, возвращающая две пары массивов — тренировочного и тестового:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
Данная функция принимает в качестве аргумента также test_size, который определяет долю, отведенную на тестовую выборку.
Теперь к самому главному — обучению модели линейной регрессии. В Scikit-learn есть класс LinearRegression, который выполнит за нас работу в Python:
from sklearn.linear_model import LinearRegression model = LinearRegression().fit(x_train, y_train)
В метод fit мы посылаем те данные, на которых ML-модель обучается. Попробуем получить предсказания на основе тестовой выборки:
y_pred = model.predict(x_test)
А как узнать, что такая модель лучшая из всех доступных? Нужно воспользоваться метриками качества.
Метрики качества для оценки работоспособности модели
Чтобы оценить работоспособность модели, применяют специальные метрики. Для задачи регрессии применяют среднеквадратическую (MSE) и абсолютную ошибки (MAE). Среднеквадратическая ошибка находится как:
![\[ MSE = \frac{1}{n}\sum(y-y_{pred})^2 \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-da5ba05efb6b7b54d19b0c69bf78689c_l3.png "Rendered by QuickLaTeX.com")
Абсолютная опускает возведение в квадрат:
![\[ MAE = \frac{1}{n}\sum|y-y_{pred}| \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-737ae55733f71ee7913da9c956052020_l3.png "Rendered by QuickLaTeX.com")
Перед оценкой стоит экспонировать тестовые и пересказанные значения, так как использовать MAE и MSE для логарифмов будет нецелесообразно, поскольку трудно будет оценить полученные результаты. Поэтому проделаем следующее:
y_test = np.exp(y_test) y_pred = np.exp(y_pred)
В модуле metrics имеется соответственно mean_squared_error, mean_absolute_error:
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
print('mse: %.3f, mae: %.3f' % (mse, mae))
В результате мы получили соответствующие результаты:
mse: 33213.153, mae: 63.478
Абсолютная ошибка составляет $63, a если взять корень от среднеквадратической ошибки, то получится $182. В целом, это большие значения, особенно с перерасчетом в рубли. Что можно сделать, чтобы улучшить модель? Здесь можно применить следующее:
- Использовать другие модели MachineLearning, в Scikit-learn их огромное количество [2];
- отфильтровать данные, например, взять только те места, в которых можно остаться только на 1-2 ночи или, наоборот, на 1 месяц;
- добавить дополнительные признаки.
Смотрите в видеообзоре, как можно обработать данные, а также как добавить геокоординаты в качестве дополнительных признаков.
Как эффективно решать задачи линейной регрессии, а также работать с другими методами Machine Learning с помощью Python, вы узнаете на практических курсах для специалистов Big Data в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
не работает plt.plot(x, lin_reg, color=’red’)
говорит, что не может найти lin_reg: NameError: name ‘lin_reg’ is not defined
lin_reg— это и есть линейная регрессия, которая задается какa*x + b. Добавил выше код