В прошлой статье мы рассмотрели что такое логистическая регрессия, сегодня разберемся с еще одним популярным методом для классификации — k ближайших соседей.
Модели для классификации: k ближайших соседей
В области Data science и машинного обучения существует множество алгоритмов, которые используются для решения задач классификации. Один из наиболее распространенных алгоритмов — это k ближайших соседей, который используется для классификации объектов на основе их близости к другим объектам в обучающей выборке. В этой статье мы рассмотрим, как использовать алгоритм k ближайших соседей для решения задач классификации в Python.
Алгоритм k ближайших соседей основан на принципе близости объектов в пространстве признаков. Он состоит в следующем: для каждого объекта из тестовой выборки находим k ближайших соседей из обучающей выборки, и классифицируем объект на основе классов его соседей. Класс, который наиболее часто встречается среди соседей, и будет классом, к которому относится исходный объект.
В Python существует множество библиотек, которые позволяют использовать алгоритм k ближайших соседей для решения задач классификации. Одной из самых популярных является библиотека Scikit-learn.
Преимущества алгоритма k ближайших соседей в задачах классификации заключаются в его простоте и интуитивности. Однако, он может быть неэффективен в случаях, когда обучающая выборка имеет большое количество атрибутов или объектов, поскольку поиск ближайших соседей может быть очень ресурсоемким.
Кроме того, выбор оптимального значения k может оказаться нетривиальной задачей. Слишком маленькое значение k может привести к переобучению модели, тогда как слишком большое значение k может привести к недообучению модели.
Для решения этих проблем существуют различные техники, такие как перекрестная проверка и оптимизация параметров, которые позволяют настроить параметры модели для достижения наилучшего качества классификации.
В Python можно легко реализовать алгоритм k ближайших соседей с помощью библиотеки Scikit-learn. Пример использования этой библиотеки для решения задачи классификации можно найти в документации библиотеки. Но мы попробуем реализовать его сами.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000 руб.
Реализация KNeighborsClassifier на Python
Хорошо, давайте реализуем собственный класс KNeighborsClassifier на Python с использованием библиотеки NumPy. Затем мы протестируем наш класс на двумерных данных и визуализируем его работу.
Сначала давайте импортируем библиотеки, которые мы будем использовать:
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
Здесь мы импортируем NumPy для работы с массивами, библиотеку matplotlib для визуализации данных и функцию make_classification из библиотеки scikit-learn для генерации синтетических данных.
Затем мы создадим класс KNeighborsClassifier:
class KNeighborsClassifier:
def __init__(self, n_neighbors=5):
self.n_neighbors = n_neighbors
def fit(self, X, y):
self.X_train = X
self.y_train = y
def predict(self, X):
y_pred = []
for i in range(len(X)):
distances = np.sqrt(np.sum((self.X_train - X[i])**2, axis=1))
nearest_indices = np.argsort(distances)[:self.n_neighbors]
nearest_labels = self.y_train[nearest_indices]
y_pred.append(np.bincount(nearest_labels).argmax())
return np.array(y_pred)
Здесь мы создаем класс KNeighborsClassifier с методами fit и predict. Конструктор класса принимает параметр n_neighbors, который указывает на количество ближайших соседей, используемых для классификации. Метод fit принимает матрицу признаков X и вектор меток y и сохраняет их в переменные self.X_train и self.y_train. Метод predict принимает матрицу признаков X и возвращает вектор предсказанных меток классов y_pred.
В методе predict мы вычисляем расстояния от каждого примера из матрицы X до каждого примера из матрицы обучающих данных self.X_train, используя формулу Евклидового расстояния. Затем мы выбираем n_neighbors ближайших соседей и получаем их метки классов. Наконец, мы возвращаем наиболее часто встречающийся класс среди ближайших соседей в качестве предсказанной метки класса.
Теперь давайте протестируем наш класс KNeighborsClassifier на двумерных данных. Для этого мы создадим синтетические данные с помощью функции make_classification и разделим наши данные на обучающий и тестовый наборы:
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_informative=2, random_state=1, n_clusters_per_class=1) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Здесь мы используем функцию train_test_split из библиотеки scikit-learn для разделения данных на обучающий и тестовый наборы в соотношении 80/20.
Теперь мы можем создать экземпляр класса KNeighborsClassifier, обучить его на обучающем наборе и выполнить валидацию на тестовом наборе:
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
y_train_pred = knn.predict(X_train)
y_test_pred = knn.predict(X_test)
print("Training Accuracy:", accuracy_score(y_train, y_train_pred)*100,'%')
print("Testing Accuracy:", accuracy_score(y_test, y_test_pred)*100,'%')
OUT:
Training Accuracy: 96.25 %
Testing Accuracy: 100.0 %
Теперь давайте создадим сетку точек, чтобы построить график решения, и используем функцию predict, чтобы определить класс каждой точки на этой сетке. Наконец, мы построим график, где каждый класс имеет свой цвет, и отображенные линии показывают границу принятия решений, разделяющую различные классы.
# Plot the decision boundary
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(10,6))
plt.pcolormesh(xx, yy, Z, cmap='coolwarm', alpha=0.2)
# Plot the data points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("K-Nearest Neighbors Classification")
plt.show()
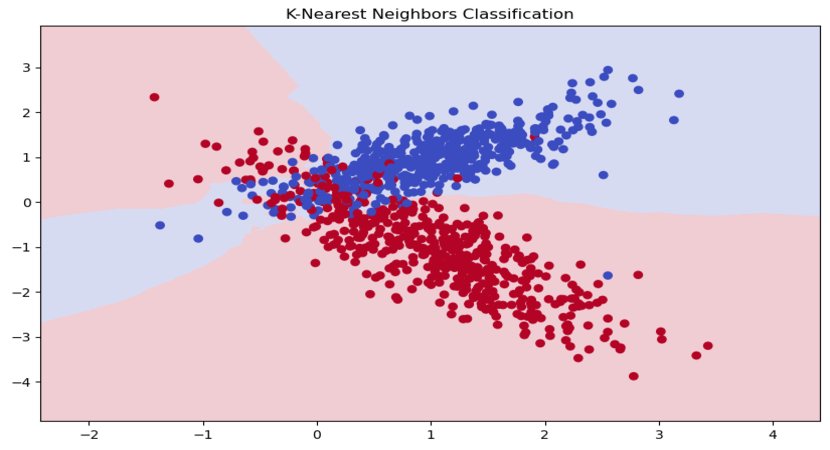
Как мы видим, K-ближайших соседей использует расстояние между точками для классификации новых точек. Если мы выберем n_neighbors=1, то границы между классами станут более сложными и, возможно, приведут к переобучению. Если мы выберем n_neighbors=10, то границы между классами станут более плавными и, возможно, приведут к недообучению. Поэтому, выбор правильного значения n_neighbors является ключевым аспектом при использовании этого алгоритма.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000 руб.
В заключение можно сказать, что алгоритм k ближайших соседей является одним из наиболее простых и эффективных алгоритмов в задачах классификации. Он может быть использован для решения множества задач в различных областях, таких как медицина, финансы, маркетинг и т.д. В Python существует множество библиотек, которые позволяют использовать этот алгоритм для решения задач классификации, что делает его доступным и удобным инструментом для многих исследователей и практиков в области Data science.
Рекомендуем посетить наш лицензированный учебный центр в Москве, который специализируется на повышении квалификации ИТ-специалистов в области машинного обучения на Python. Там вы сможете пройти практические курсы «Машинное обучение на Python» и узнать много полезного.
Источники:

