Проблема классификации объекта на изображении уже решена – сверточные нейронные сети (Convolutional Neural Networks, CNN) уже неплохо справляются с определением кошек или собак. Но если на изображении много объектов, которые нужно найти, задача сразу усложняется. На смену обычным сверточным нейросетям пришли более сложные модели. В этой статье рассмотрим 3 популярных способа детектирования изображений методами Deep Learning: R-CNN, Fast R-CNN и Faster R-CNN.
Что такое детектирование объектов
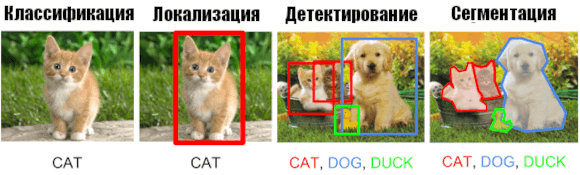
Распознавание образов – это общий термин, описывающий круг задач компьютерного зрения, которые решают проблему обнаружения объектов на изображении или видеокадрах. К ним относятся классификация изображения, локализация объектов, детектирование объектов и сегментация. Проведем между ними грань:
- Классификация изображений, где определяется тип или класс объектов на изображении, например, человек, кошка, самолет и т.д.
- Локализация объектов, когда требуется найти объекты и отметить как-то их, например, прямоугольником.
- Детектирование объектов, когда нужно найти объекты, отметить их и классифицировать.
- Сегментация, когда нужно найти объекты и отделить их от заднего фона путем подсвечивания.
На следующем изображении показано, как решаются вышеперечисленные задачи на примере одиночного объекта и множества объектов (нажмите, чтобы увеличить):
Для детектирования объектов существуют разные методы глубокого обучения (deep learning). Сначала рассмотрим семейство R-CNN.
R-CNN
Архитектура R-CNN (Region-Based Convolutional Neural Network) была разработана в 2014 году Ross Girshik и другими [1]. В основе этого метода лежит следующий алгоритм:
- Нахождение потенциальных объектов на изображении и разбиение их на регионы cпомощью метода selective search [2].
- Извлечение признаков каждого полученного региона с помощью сверточных нейронных сетей.
- Классифицирование обработанных признаков с помощью метода опорных векторов (SVM, Support Vector Machine) и уточнение границ регионов с помощью линейной регрессии.
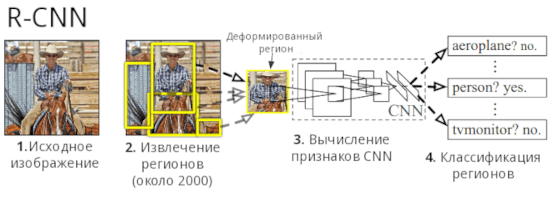
В итоге, получаем отдельные регионы с объектами и их классами. В центре стоят сверточные нейронные сети, которые показывают хорошую точность на примере изображений. Но у такой архитектуры есть недостатки:
- Энергозатратный – требует большого количество времени на обучение. В методе selective search изображение сначала сегментируется на 2000 регионов, которые затем в ходе итерирования с помощью жадного алгоритма объединяются в более крупные регионы. Кроме того, сами сверточные сети тоже требует вычислительных мощностей.
- Не может быть использован для видео. Опять же из вытекает из недостатка выше, так как все промежуточные методы энергозатратны, поэтому кадры просто не будут успевать обрабатываться.
- Selective search не является алгоритмом машинного обучения, поэтому могут возникнуть проблемы с выявлением потенциальных объектов на разных изображениях.
На данный момент модель R-CNN устарела и не применяется.
Fast R-CNN
Недостатки R-CNN привели авторов в 2015 году к улучшению модели. Они назвали ее Fast R-CNN [3]. В ее основе лежит следующая архитектура:
- Изображение подается на вход сверточной нейронной сети и обрабатывается selectivesearch. В итоге, имеем карту признаков и регионы потенциальных объектов.
- Координаты регионов потенциальных объектов преобразуются в координаты на карте признаков.
- Полученная карта признаков с регионами передается слою RoI (Region of Interest) polling layer. Здесь на каждый регион накладывается сетка размером HxW. Затем применяется MaxPolling для уменьшения размерности. Так, все регионы потенциальных объектов имеют одинаковую фиксированную размерность.
- Полученные признаки подаются на вход полносвязного слоя (Fully-conectedlayer), который передается двум другим полносвязным слоям. Первый с функцией активацией softmax определяет вероятность принадлежности классу, второй – границы (смещение) региона потенциального объекта.
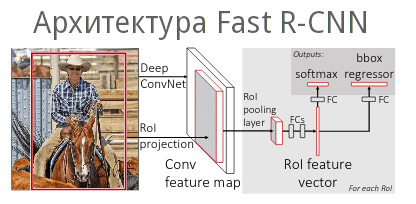
Fast R-CNN показывает чуть более высокую точность и большой прирост времени обработки в отличие от R-CNN, так как не требуется подавать все регионы на сверточный слой. Но тем не менее, данный метод использует затратный Selective Search. Поэтому авторы пришли к Faster R-CNN.
Faster R-CNN
Авторы продолжили улучшение над Fast R-CNN и в 2016 предложили Faster R-CNN. Они разработали собственный метод локализации объекта взамен Selective Searc — RPN (Region Proporsal Networks) [4]. В основе RPN лежит система якорей. Архитектура Faster R-CNN образована следующим образом:
- Изображение подается на вход сверточной нейронной сети. Так, формируется карта признаков.
- Карта признаков обрабатывается слоем RPN. Здесь скользящее окно проходится по карте признаков. Центр скользящего окна связан с центром якорей. Якоря – это области, имеющие разные соотношения сторон и разные размеры. Авторы используют 3 соотношения сторон и 3 размера. На основе метрики IoF(intersection-over-union), степени пересечения якорей и истинных размеченных прямоугольников, выносится решение о текущем регионе — есть объект или нет.
- Далее используется алгоритм FastCNN: карта признаков с полученными объектами передаются слою RoI с последующей обработкой полносвязных слоев и классификацией, а также с определением смещения регионов потенциальных объектов.
Модель Faster R-CNN справляется немного хуже с локализацией, но работает быстрее Fast R-CNN. Сейчас необязательно разбираться со всеми архитектурами, так имеются уже предобученные модели, например, tensorflow models. Также смотрите в видеобзоре, как на практике применять предобученные модели для детектирования изображений в Tensorflow.
Как применять методы детектирования изображений на реальных Big Data проектах с помощью Python, вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.