Продолжим говорить о сверточных нейронных сетях (CNN) в TensorFlow. В этой статье мы расскажем вам, как обучать модели CNN на данных с цветными изображениями кошек и собак. Читайте у нас: раскладывание файлов по папкам в Python, конструирование сети, преобразование изображений (Data augmentation) с целью преодоления переобучения (overfitting) в TensorFlow.
Датасет: кошки vs собаки
Построим модель машинного обучения на основе датасета с кошками и собаками. Он доступен для скачивания (можно использовать Kaggle API, как описано здесь). Всего датасет содержит 12500 тренировочных и 12500 тестовых изображений по половине на кошек и собак.
Мы не будем использовать все изображения для обучения. Тренировочные данные разделим на следующие категории:
- 2000 изображений (1000 собак и 1000 кошек) пойдёт на обучение (train)
- 1000 изображений (500 собак и 500 кошек) на валидацию (validation)
- 1000 изображений (500 собак и 500 кошек) на тестирование (test)
Python-библиотека pathlib пригодится для оперирования путями.
Создаем папки
Создадим отдельные папки, которые будут использованы для обучения, валидации и тестирования. Эти папки будут находиться в директории dataset. Вот так выглядит Python-код:
def create_dir(dir, children):
new_dir = dir / children
new_dir.mkdir()
return new_dir
base_dir = create_dir(Path('.'), 'dataset')
train_dir = create_dir(base_dir, 'train')
test_dir = create_dir(base_dir, 'test')
valid_dir = create_dir(base_dir, 'validation')
В каждой папке создадим директории cats и dogs, которые будут содержать изображения кошек и собак соответственно.
train_dogs_dir = create_dir(train_dir, 'dogs') train_cats_dir = create_dir(train_dir, 'cats') test_dogs_dir = create_dir(test_dir, 'dogs') test_cats_dir = create_dir(test_dir, 'cats') valid_dogs_dir = create_dir(valid_dir, 'dogs') valid_cats_dir = create_dir(valid_dir, 'cats')
Копируем изображения из одной папки в другую
В папке с исходным датасетом изображения находятся в директории train/train. Файлы с изображениями имеют названия животное.номер.jpg, например, dog.14.jpg. Мы воспользуемся этим шаблоном для перечисления изображений, а для копирования файлов будем использовать библиотеку shutil. Вот так выглядит созданная в Python функция:
import shutil
def copy_files(src, dest, name, start, stop):
fnames = [f'{name}.{i}.jpg' for i in range(start,stop)]
for fname in fnames:
src_file = src / fname
dest_file = dest / fname
shutil.copy(src_file, dest_file)
Теперь применим её для каждой папки:
src = Path('.') / 'train' / 'train'
copy_files(src, train_dogs_dir, 'dog', 0, 1000)
copy_files(src, train_cats_dir, 'cat', 0, 1000)
copy_files(src, test_dogs_dir, 'dog', 1000, 1500)
copy_files(src, test_cats_dir, 'cat', 1000, 1500)
copy_files(src, valid_dogs_dir, 'dog', 1500, 2000)
copy_files(src, valid_cats_dir, 'cat', 1500, 2000)
Можем проверить количество:
>>> len(list(train_dogs_dir.iterdir())) 1000 >>> len(list(test_cats_dir.iterdir())) 500 >>> len(list(valid_cats_dir.iterdir())) 500
Конструирование сети
Текущая модель CNN похожа на сеть TensorFlow из предыдущей статьи. Только на вход подаём изображения с высотой и шириной (150,150) в RGB, следовательно глубина входа равна 3. Самый последний полносвязный слой имеет 1 нейрон с функцией активацией sigmoid, поскольку решается задача бинарной классификации.
from tensorflow.keras import models
from tensorflow.keras import layers
model = models.Sequential([
layers.Conv2D(32, (3,3), activation='relu',
input_shape=(150,150,3)),
layers.MaxPooling2D((2,2)),
layers.Conv2D(64, (3,3), activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Conv2D(128, (3,3), activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Conv2D(128, (3,3), activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Flatten(),
layers.Dense(512, 'relu'),
layers.Dense(1, 'sigmoid') # 1 нейрон – кошка или собака
])
Всего такая сеть содержит 3,453,121 параметров (при вызове model.summary()).
Генерация изображений
Мы не можем передать на вход сети CNN бинарные файлы, так как нейронные сети работают с тензорами. Для конвертирования изображений в тензоры в TensorFlow используется ImageDataGenerator, который также может изменять изображения. В первую очередь, необходимо перевести значения пикселей из диапазона [0,255] в [0,1], поскольку алгоритмы Machine Learning работают с небольшими значениями. Инициализация генератора изображений в Python:
from tensorflow.keras.preprocessing.image import ImageDataGenerator train_datagen = ImageDataGenerator(rescale=1./255) test_datagen = ImageDataGenerator(rescale=1./255) valid_datagen = ImageDataGenerator(rescale=1./255)
Далее применим генерацию данных в TensorFlow для наших изображений, вызвав метод flow_from_directory. Нам нужно указать папку с изображениями, размер выходного тензора (150,150), размер пакета тензоров, а также тип выполнения задачи:
def image_generator(dategen, dir):
return dategen.flow_from_directory(
dir,
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
train_generator = image_generator(train_datagen, train_dir)
test_generator = image_generator(test_datagen, test_dir)
valid_generator = image_generator(valid_datagen, valid_dir)
Результатом является генератор, который содержит пакет тензоров с формой (20,150,150,3) и метки классов (кошка/собака) с формой (20,).
Обучение модели TensorFlow
Осталось только обучить модель. Для этого сначала нужно её скомпилировать. Выберем оптимизатор Adam и функцию потерь Binary Crossentropy, так как решается задача бинарной классификации.
Кроме того, используем TensorBoard для визуализации данных. Обучение модели происходит через метод fit. Поскольку мы используем генератор изображений, то данные могут генерироваться бесконечно. Чтобы этого избежать, нужно указать аргумент steps_per_epoch, значение которого ограничит генерацию изображений для каждой эпохи. В нашем случае один пакет содержит 20 изображений, поэтому для извлечения всех 2000 изображений потребуется 100 шагов. Итак, полный код на Python выглядит так:
from datetime import datetime
from tensorflow.keras.callbacks import TensorBoard
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=valid_generator,
callbacks=[tensorboard_callback])
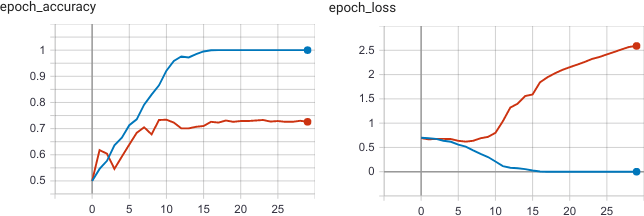
Обучение на 30 эпохах в Google Colab с использованием GPU заняло 4 минуты. Как видим, на рисунке ниже после 10 эпохи произошло переобучение (overfitting): функция потерь на валидационной выборке (оранжевая линия) стала увеличиваться, а точность не изменяться.
Data Augmentation (преобразование данных) в TensorFlow
Если бы мы использовали все 12500 изображений, то возможно получили бы лучшие результаты. Но очень часто приходится сталкиваться с нехваткой данных. При работе с изображениями можно воспользоваться преобразованиями изображений (Data Augmentation), которые даёт ImageDataGenerator. До этого мы только изменяли значения пикселов. Так, изображения можно поворачивать, отзеркаливать, приближать, двигать и т.д. Для этого указываются соответствующие аргументы.
# Преобразование данных:
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=.2,
height_shift_range=.2,
shear_range=.2,
zoom_range=.2,
horizontal_flip=True,
)
Полный список доступных изменений ImageDataGenerator можно посмотреть в документации. Посмотрим, как он трансформирует изображения. Вот так выглядит Python-код:
from tensorflow.keras.preprocessing import image
import matplotlib.pyplot as plt
img_path = train_cats_dir / 'cat.1.jpg'
img = image.load_img(img_path, target_size=(150,150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape) # изменение формы на (1,150,150,3)
i = 0
for batch in train_datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i == 2:
break
plt.show()

Также для предотвращения переобучения мы добавим слой Dropout перед полносвязным слоем, который будет отключать один из нейронов с вероятностью 0.5. Теперь мы можем снова обучить модель с учётом преобразований.
model = models.Sequential([
## CЛОИ CNN
layers.Dropout(0.5), # Отключит нейрон с вероятностью 0.5
layers.Flatten(),
layers.Dense(512, 'relu'),
layers.Dense(1, 'sigmoid')
])
train_generator = image_generator(train_datagen, train_dir)
model.fit(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=valid_generator,
callbacks=[tensorboard_callback])
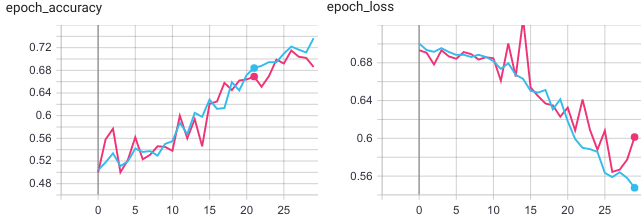
Из рисунка видно, что на 30 эпохах модель не достигла переобуения, поэтому можно было продолжить обучение.
Также вы можете ознакомиться с практическим применением моделей CNN для распознавания объектов на изображении:
Ещё больше подробностей о преобразовании данных (Data augmentation) в TensorFlow и обучении моделей Machine Learining для решения задач компьютерного зрения на примерах Data Science, вы узнаете на специализированном курсе «VISI: Computer vision на Python» в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.