Сверточные нейронные сети (CNN) являются одними из самых эффективных сетей Deep Learning. Сегодня мы расскажем вам о CNN в фреймворке TensorFlow. Читайте в этой статье: загрузка и подготовка датасета MNIST, создание модели CNN, а также визуализация с TensorBoard.
Датасет MNIST
Рассмотрим датасет MNIST, который содержит изображения с рукописными цифрами. В Keras есть API для загрузки датасетов. Инициализация MNIST в Python выглядит следующим образом:
import tensorflow.keras as keras (x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_trainиx_test— тренировочный и тестовый набор изображений в оттенках серого и размером (28,28). Всего тренировочных изображений 60000, а тестовых — 10000y_trainиy_test— соответствующие метки классов (от 0 до 9)
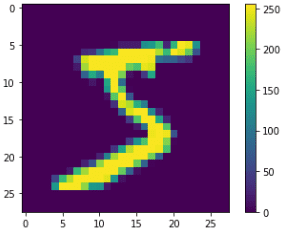
Если мы взглянем на тренировочный набор, то увидим, что первое изображение — это цифра 5, второе — цифра 0 и т.д.
>>> y_train array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
Мы также можем взглянуть на само изображения с помощью Python-библиотеки Matplotlib:
import matplotlib.pyplot as plt plt.imshow(x_train[0, :, :]) plt.colorbar()
Готовим датасет
Алгоритмы Machine Learning в TensorFlow работают с вещественными числами в небольших диапазонах. Но пикселы исходных изображений варьируются от 0 до 255. Кроме того, CNN в TensorFlow принимают на вход 3-мерный признак (ширина, высота, глубина). Глубина изображения в оттенках серого равна 1, у RGB — 3. Поэтому конвертируем наши изображения в оттенках серого согласно данным условиям. Код на Python следующий:
x_train = x_train.reshape((60000, 28, 28, 1))
x_train = x_train.astype('float32') / 255
x_test = x_test.reshape((10000, 28, 28, 1))
x_test = x_test.astype('float32') / 255
Нам также необходимо преобразовать метки классов в категориальные признаки, т.е. каждой цифре должен соответствовать один из десяти классов. Для этого есть инструментарий Keras:
from keras.utils import to_categorical y_train = to_categorical(y_train) y_test = to_categorical(y_test)
Преобразованные метки классов теперь имеют новый вид.
>>> y_train
array([[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], # Цифра 5
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], # Цирфа 0
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], # Цифра 4
...,
dtype=float32)
Создаем модель CNN
Слой свёртки принимает на вход 3-мерный признак. Помимо него, целесообразно использовать слой Pooling для уменьшения размерности. Уменьшение размерности поможет сети углубиться в детали локальных представлений, а также уменьшить количество обучаемых коэффициентов. Поскольку решается задача классификации, в конце архитектуры добавим полносвязные (Dense) слои.
Все необходимые слои находятся в модуле Keras. Для инициализации CNN в TensorFlow используется слой Conv2D, а для уменьшения размерности MaxPooling2D. Перед тем как передать результаты сверточных сетей полносвязному, нужно выпрямить выходной тензор с помощью Flatten. В итоге, архитектура выглядит вот так:
from keras import models
from keras import layers
model = models.Sequential([
layers.Conv2D(32, (3,3), activation='relu', # (3,3) - фильтр
input_shape=(28,28,1)),
layers.MaxPooling2D((2,2)), # фильтр (2,2) для пулинга
layers.Conv2D(64, (3,3), activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Conv2D(64, (3,3), activation='relu'),
layers.Flatten(),
layers.Dense(64, 'relu'),
layers.Dense(10, 'softmax')
])
Архитектура оканчивается полносвязным слоем с 10-ю нейронами и функцией активации softmax, которая применяется для многоклассовой классификации. Заметим, для CNN слоёв используется фильтр (3,3), а их количество увеличивается по мере углубления сети, а слои Pooling состоят из фильтра (2,2). Такие значения очень часто применяются в моделях со сверточными нейронными сетями.
Метод summary показывает архитектуру сети и её параметры. Вот так выглядит Python-код:
>>> model.summary() Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 26, 26, 32) 320 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 11, 11, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 3, 3, 64) 36928 _________________________________________________________________ flatten (Flatten) (None, 576) 0 _________________________________________________________________ dense (Dense) (None, 64) 36928 _________________________________________________________________ dense_1 (Dense) (None, 10) 650 ================================================================= Total params: 93,322 Trainable params: 93,322 Non-trainable params: 0
Компилируем и обучаем модель
Следующим шагом идёт компиляция модели. Для обновления весов используются оптимизаторы. В TensorFlow их насчитывается 9. Одним из популярных является Adam. Воспользуемся им.
Поскольку решается задача многоклассовой оптимизации, то в качестве функции потерь следует использовать Categorical Crossentropy. Для двух классов применялась бы Binary Crossentropy. В качестве метрики используем Accuracy (опять же по причине задачи классификации). В результате, компиляция модели TensorFlow выглядит следующим образом:
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
Теперь осталось только обучить модель. Обучим модель на 5 эпохах обучения и 64 пакетах (количество изображений за 1 обновление градиента). Следующий код на Python это демонстрирует:
model.fit(x_train, y_train, epochs=5, batch_size=64)
Оценим модель на проверочной выборке. Точность на ней составила 99%, т.е. модель практически всегда права, когда дело касается распознавания рукописных цифр:
>>> test_loss, test_acc = model.evaluate(x_test, y_test) >>> test_loss 0.03384203836321831 >>> test_acc 0.9911999702453613
Визуализация с TensorBoard
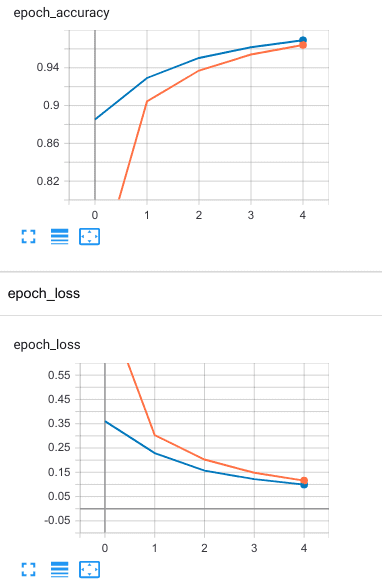
Кроме того, правильным решением будет построение диаграмм изменения точности и функции потерь с увеличением эпохи обучения. Для этого можно использовать Matplotlib. Однако для большей наглядности стоит воспользоваться таким инструментом визуализации, как TensorBoard [1].
Для этого в методе обучения fit нужно указать соответствующий обратный вызов (callback). В него нужно передать объект TensorBoard, с указанным путём сохранения процесса обучения. Мы сохраним под нынешней датой и временем. В итоге, в Python это выглядит так:
from datetime import datetime
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
log_dir = "logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
batch_size=64,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])
Теперь нужно загрузить расширение TensorBoard:
%load_ext tensorboard
а затем вызвать TensorBoard:
%tensorboard --logdir logs/fit
Ещё больше подробностей о TensorFlow и создании моделей машинного обучения на реальных примерах Data Science, вы узнаете на специализированном курсе «PYNN: Введение в Нейронные сети на Python» в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.