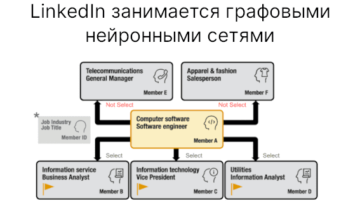
Команда Meta AI анонсировала выход новой открытой модели компьютерного зрения под названием SEER (SElf-SupERvised) 10B. Особенность этой модели в том, что в ней задействовано самообучения (self-supervised), т.е. она обучаете на случайных изображениях из Интернета без помощи со стороны людей и без каких-либо меток. Изображение поступает на обычные алгоритмы Computer Vision, которые генерирует выходное изображение.
Первый анонс SEER состоялся прошлой весной [1]. Количество параметров с тех пор увеличилось с 1 до 10 млрд. Теперь это самая крупная модель в области компьютерного зрения.
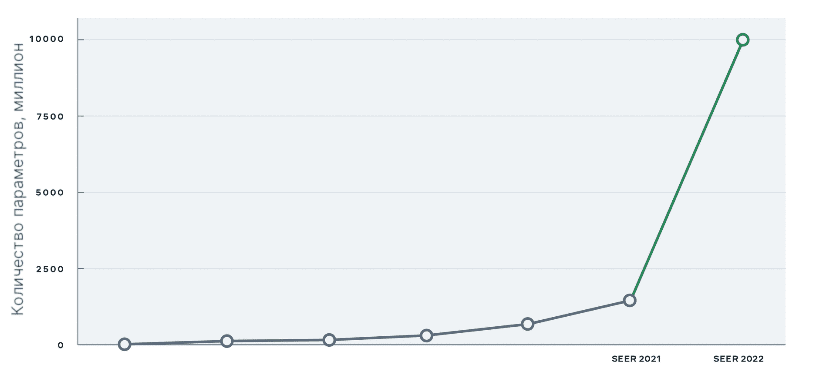
Из-за такого размера SEER может извлекать признаки более высокого качества и находить связи между объектами в датасетах с триллионами случайных изображений. Такая модель справляется с проблемами, с которыми встречаются модели без учителя (unsupervised). SEER обходит по производительности другие модели на основании разработанных оценках Meta AI research [2]. Традиционные системы компьютерного зрения обучаются на изображениях, собранных в США и богатых странах Европы, поэтому они плохо работают с изображениями из других мест. Модель SEER же в этом плане собирает данные ото всюду, также она показывает лучшие характеристика с учетом пола, цвета кожи и возраста. Она даже может определить геоположение с высокой точностью. Ей под силу справиться с определением животных на художественной иллюстрации, разобраться с дефектами: камуфляжем, размытием, движением, необычной перспективой.
Больше скорости и производительности
Разработчики изучали и проводили валидацию на более чем 50 оценках производительности, включая точность, робастность, мелкозернистое распознавание, разные датасеты для классификации с медицинскими, спутниковыми, отсканированными изображениями. SEER 10B превзошла все модели с учителем и с самообучением в тесте ImageNet с 70% точностью. А также 90.6% в тесте CopyDays.
SEER умеет находить скрытые детали. Так, например, несмотря на то, что модель обучена только на изображениях без информации о месторасположении или других метаданных, она может группировать схожие характеристики различных культур. Например, тематика “свадьбы” со всего мира сгруппирована вместе в пространстве признаков.
Защита конфиденциальности
Последние [3] показывают, что некоторые модели уязвимы для извлечения ценной информации. В некоторых случаях злоумышленники могут выполнить запрос модели и реконструировать некоторые образцы из тренировочного датасета. Поэтому разработчики занимаются и безопасностью модели.
Код курса
VISI
Ближайшая дата курса
Продолжительность
ак.часов
Стоимость обучения
0 руб.
Если же вы хотите больше узнать о методах компьютерного зрения, то посетите наш курс «VISI: Computer vision на Python» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.