
День за днем количество данных увеличивается настолько, что прошлые инструменты обработки начинают устаревать. Не секрет, что Pandas не предназначен для работы с Big Data. Тогда на замену придут такие Python-библиотеки, как Vaex и Dask. Читайте в этой статье: отличия между Vaex и Dask, скорость выполнения операций на локальном компьютере и в облаке каждой из библиотек.
Что такое Dask и Vaex
Dask — это библиотека анализа данных с обеспечением параллельных вычислений и масштабируемой производительностью, а также с интеграцией с другими Python-инструментами: Numpy, Pandas и Scikit-learn. Библиотека имеет в основе существующие API-интерфейсы на Python и структуры данных, чтобы упростить переключение между библиотеками.
Vaex — это высокопроизводительная библиотека Python для создания датафреймов (аналогичных Pandas), визуализации и агрегирования больших данных (Big Data). Она может вычислять базовую статистику для более чем миллиарда строк за одну секунду. В отличие от Dask, не имеет полной интеграцией с другими библиотеками.
Датафреймы Dask и Vaex не полностью совместимы с Pandas, но некоторые наиболее распространенные операции обработки данных всё же поддерживаются обоими библиотеками. Dask больше ориентирован на масштабирование с вычислениями на кластерах, в то время как Vaex упрощает работу с большими наборами данных на одной машине.
Vaex vs Dask
Ниже вы можете видеть, за сколько секунд Vaex и Dask выполняют различные операции над датасетом размером 100 Гб. Операции выполнялись в облаке AWS. Отметим, что Pandas не смог прочитать такие файлы, и Jupyter Notebook завис.
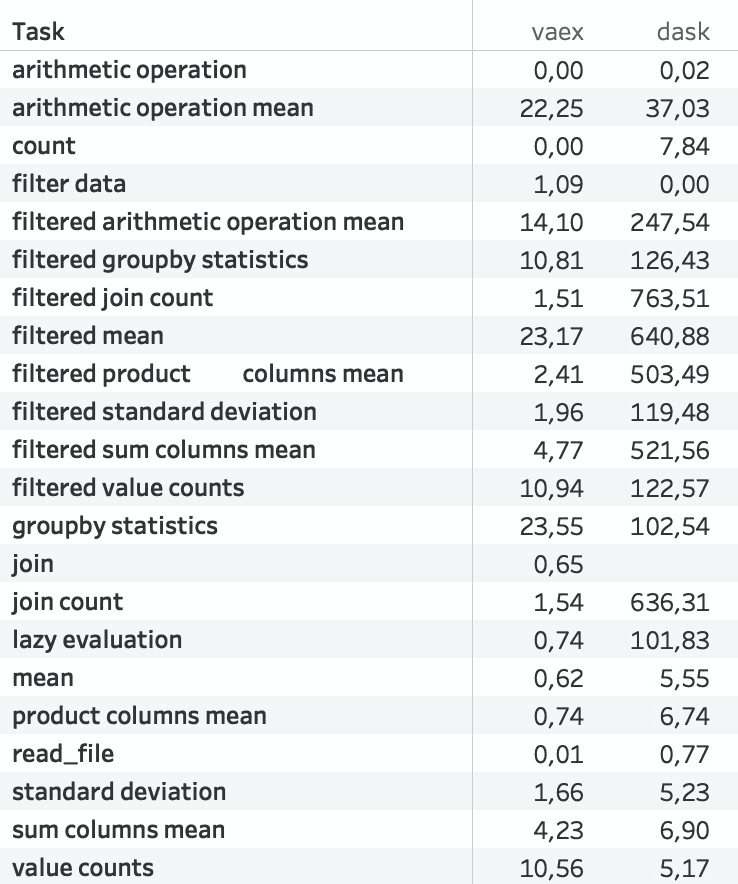
Vaex
Попробуем посмотреть, что происходит при чтении файлов размером 36 Гб на локальном компьютере. Чтобы прочесть CSV-файл большого размера, в Vaex рекомендуется конвертировать в HDF5 (Иерархический формат данных). Следующий код на Python демонстрирует преобразование из текстового формата CSV в двоичный формат HDF5:
import glob
import vaex
csv_files = glob.glob('csv_files/*.csv')
chunk = 5_000_000
for i, csv_file in enumerate(csv_files, 1):
for j, dv in enumerate(vaex.from_csv(csv_file, chunk_size=chunk)):
dv.export_hdf5(f'file_{i:02}_{j:02}.hdf5')
Vaex потребовалось 405 сек (7 мин), чтобы преобразовать файлы CSV (36 Гб) в файлы HDF5 с 16 Гб вместе. Таким образом, преобразование из текстового в двоичный формат уменьшило размер файлов в двое.
Чтение HDF5 в Vaex
Код на Python для открытия файла HDF5 в Vaex выглядит следующим образом:
dv = vaex.open('hdf5_files/*.hdf5')
Vaex потребовалось 1218 сек (20.3 мин), чтобы прочитать файлы HDF5. Чудо не произошло. Хотя, как сказано в документации Vaex, чтение больших файлов должно происходить мгновенно.
Вывод первых строк в Vaex
Для вывода первых строк используется метод head:
dv.head()
Vaex потребовалось 1189 сек (20 мин), чтобы их отобразить. Неизвестно почему отображение первых 5 строк заняло так много времени.
Dask
Попробуем повторить описанные выше операции в Dask. Также конвертируем CSV-файлы в формат HDF5. В Dask для преобразования в HDF5 используется метод to_hdf:
import dask.dataframe as dd
ds = dd.read_csv('csv_files/*.csv')
ds.to_hdf('file.hdf5', key='table')
Dask потребовалось 763 сек (12 мин) для чтения и преобразования. Кстати, в документации сказано, что рекомендуется использовать формат Apache Parquet вместо HDF5.
Вывод первых строк в Dask
Код на Python для вывода первых строк в Dask:
ds.head()
Dask потребовалось 9 секунд, чтобы вывести первые 5 строк файла. Это сильно отличается от того, что делает Vaex.
Так что же выбрать Vaex или Dask
Vaex показал очень высокие результаты при работе в облаке. Но вот на локальном компьютере больше зарекомендовал себя Dask.
Стоит помнить, что Dask основан на Pandas, поэтому может интегрироваться и с другими Python-библиотеками: Scikit-learn, NumPy, Scipy. С ними намного лучше анализировать данные, выполнять машинное обучение и проверять статистические гипотезы.
Еще больше подробностей об обработке больших данных с помощью различных библиотек в рамках решения реальных задач Data Science вы узнаете на нашем специализированном курсе «DPREP: Подготовка данных для Data Mining на Python» в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.

