Продолжим работать с базами данных со встроенной Python-библиотекой — sqlite3, которая предоставляет интерфейс SQLite. На практическом примере расскажем о создании таблиц, построим отношение один-ко-многим и покажем результаты в SQL-клиенте — DBeaver.
Интерфейс SQLite в Python
В прошлой статье мы разобрались с интерфейсом sqlite3, а именно:
- как устанавливать соединение с базой данных,
- как совершать транзакции, используя контекстный менеджер with,
- как инициализировать объект Cursor, полезный для получения данных,
- как писать безопасные запросы, используя
?или:value.
Теперь можем приступить к созданию таблиц.
Создаем таблицу user
Для выполнения запросов используется метод execute. Пусть будет таблица User с тремя атрибутами: id, имя, возраст. Код в Python для создания таблицы будет выглядеть так:
import sqlite3
con = sqlite3.connect("test.db")
cur = con.cursor()
with con:
cur.execute("""
CREATE TABLE user (
id INT NOT NULL PRIMARY KEY,
name TEXT,
age INTEGER
);
""")
Типов данных в SQLite всего 5: NULL, INT, REAL, TEXT, BLOB. Последний тип данных — это Binary Large OBjects, т.е. бинарные объекты (документы, рисунки, аудио).
Добавляем данные
Добавить можно как одну запись, так и список записей. Во втором случае используется executemany. Выполним два запроса в Python:
query = 'INSERT INTO USER (id, name, age) values(?, ?, ?)'
data = [
(2, 'Vova', 25),
(3, 'Anna', 21),
(4, 'Kolya', 19)
]
with con:
cur.executemany(query, data)
data = (1, "Sasha", 32)
with con:
cur.execute("INSERT INTO user (id, name, age) values(?, ?, ?)", data)
Выводим данные пользователей
Используя метод fetchall объекта Cursor, можно получить все записи, например:
cur.execute("SELECT * FROM user WHERE age <= 22").fetchall()
# [(3, 'Anna', 21), (4, 'Kolya', 19)]
В то время как метод fetchone выдаст только первую:
cur.execute("SELECT * FROM USER WHERE age <= 22").fetchone()
# (3, 'Anna', 21)
Отношение один-ко-многим
Воспроизведем отношение один-ко-многим. Допустим, каждый пользователь знает несколько иностранных языков. Для этого нам понадобятся еще две таблицы: таблица с языками и таблица, которая связывает id пользователя и id языка.
Таблица языков с Python-кодом будет выглядеть так:
with con:
cur.execute("""
CREATE TABLE language (
id INT NOT NULL PRIMARY KEY,
name TEXT
);
""")
Таблица, которая связывает id пользователя и id языка, должна иметь внешние ключи этих id, которые вместе образуют первичный ключ. В итоге, это выглядит так:
with con:
cur.execute("""
CREATE TABLE user_language (
user_id INT,
language_id INT,
PRIMARY KEY(user_id, language_id),
FOREIGN KEY(user_id) REFERENCES user(id),
FOREIGN KEY(language_id) REFERENCES language(id)
);
""")
Добавляем данные языков
Добавим несколько языков в таблицу Language. Запрос в Python:
data = [
(1, "english"),
(2, "spanish"),
(3, "french")
]
with con:
cur.executemany("INSERT INTO language VALUES(?, ?)", data)
Теперь обозначим пользователей, которые знают иностранные языки:
data = [
(1, 2), # Саша знает испанский
(2, 1), # Вова знает английский
(2, 2), # Вова еще знает испанский
(3, 3), # Анна знает французский
]
with con:
cur.executemany("INSERT INTO user_language VALUES(?, ?)", data)
Выводим данные пользователей, знающих иностранные языки
Выведем пользователей и языки, которые они знают. Нам нужно только записать условие совпадения идентификаторов. В Python запрос выглядит следующим образом:
cur.execute("""
SELECT user.name, language.name
FROM user, language, user_language
WHERE (user.id = user_language.user_id AND
language.id = user_language.language_id)
""").fetchall()
На выходе получили:
[('Sasha', 'spanish'),
('Vova', 'english'),
('Vova', 'spanish'),
('Anna', 'french')]
После работы с базой данных следует закрыть соединение:
con.close()
SQL-клиент DBeaver для просмотра результатов
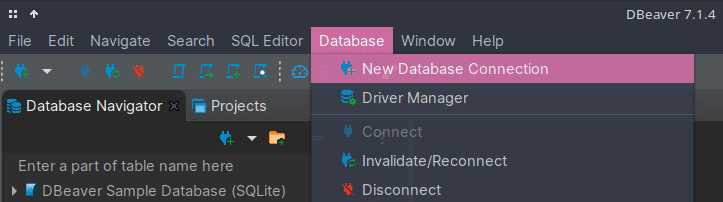
Можно получить доступ к базам данных с помощью SQL-клиента, например, свободного и открытого DBeaver. Запустив DBeaver, необходимо установить соединение с базой данных во вкладке Базы данных (Database), как это показано на рисунке ниже. После этого указать тип БД и путь к ней.
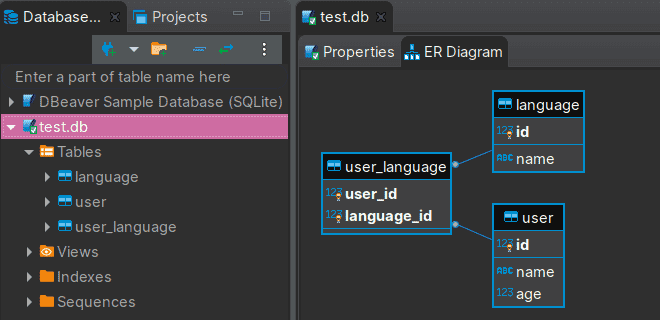
В DBeaver также можно писать запросы. Кроме этого, мы можем посмотреть на ER-диаграмму созданных таблиц в соответствующей вкладке. На рисунке ниже это проиллюстрировано.

Использованный код доступен в репозитории на Github. В следующей статье поговорим о интеграции SQLite с Python-библиотекой Pandas. А о том, как работать с данными в Python на проектах Data Science, вы узнаете на курсах в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.

