Прежде чем приступить к созданию модели машинного обучения (Machine Learning) и начать прогнозировать или классифицировать, стоит провести предварительную обработку данных. В этой статье мы рассмотрим четыре примера работы с датасетом на Python.
Датасет с отелями Нью-Йорка
В прошлый раз мы говорили о построение географических карт на примере датасета с нью-йоркскими апартаментами (отелями), которые можно арендовать на некоторое время. Поэтому воспользуемся им. В первую очередь, прочитаем и выведем некоторые его атрибуты:
import pandas as pd
data = pd.read_csv('../AB_NYC_2019.csv')
data.head()
В дальнейшем будем работать не со всеми районами Нью-Йорка, а только Бруклином:
data = data[data['neighbourhood_group'] == 'Brooklyn']
Трансформация признаков: из категориальных в числовые
Компьютер в действительности работает с числами, поэтому строковые категориальные значения следует перевести в числовые. В датасете имеется атрибут room_type — тип комнаты, который может принимать значения Private room, Entire home/apt, Shared room:
>>> data.room_type.unique() array(['Private room', 'Entire home/apt', 'Shared room'], dtype=object)
В Python-библиотеке Pandas имеется функция get_dummies , которая конвертирует категориальные значения в числовые. На вход она принимает массив или объект DataFrame:
pd.get_dummies(data.room_type)
Таким образом, мы получаем новый DataFrame:
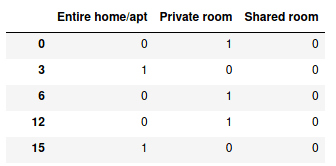
Каждая строка в этом DataFrame-объекте соответствует одному типу комнаты.
Избавляемся от пропусков: как заполнить пустые значения
Часто в данных могут отсутствовать некоторые значения, тогда им присваиваются Nan. Наш датасет содержит пустые записи в атрибутах last_review и reviews_per_month :
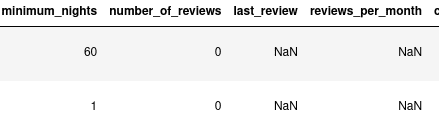
В таких случаях можно сделать следующее:
- удалить строки с Nan,
- удалить атрибуты с Nan,
- заполнить Nan нейтральными значениями. т.е. такие, которые не окажут значительного влияния на обучение.
Если пользоваться третьим методом, то пустые значения reviews_per_month можно заполнить нулями:
data['reviews_per_month'] = data['reviews_per_month'].fillna(0)
В ситуации с last_review так не получится, так как этот атрибут содержит дату последнего отзыва. Но мы можем создать атрибут days_from_last_review , который будет отвечать за свежесть последнего отзыва. Самая последняя дата всего датасета соответствует 2019.7.10. Присвоим эту дату Nan-значениям:
from datetime import datetime
date_now = datetime(2019,7,10)
data['last_review'] = data['last_review'].fillna(date_now.strftime('%Y-%m-%d')) # конвертируем в строковое значение
data['last_review'] = data['last_review'].apply(lambda x: datetime.strptime(x, '%Y-%m-%d'))
Отметим, все значения last_review конвертируются в объект datetime. Это делается для того, чтобы в дальнейшем работать с датами. А теперь возьмем разницу между датой 2019.7.10 и значениями атрибута last_review, тогда у полей с Nan после вычислений будет 0:
data['days_from_last_review'] = data['last_review'].apply(lambda x: (date_now - x).days)
Так, получили новый атрибут days_from_last_review:
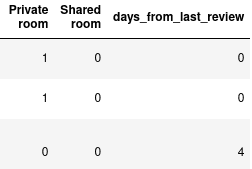
days_from_last_reviewВсе будет нормально: стандартизируем данные
Для повышения точности ML-моделирования входные данные часто подвергают нормализации и/или стандартизации.
Нормализация необходима для приведения данных к диапазону от 0 до 1. Это объясняется тем, что многим алгоритмам машинного обучения удобнее работать с этим диапазоном. В Python-библиотеке Scikit-learn есть для этого классы MinMaxScaler и RobustScaler.
Стандартизацию применяют для приведения данных к нормальному распределению с математическим ожиданием равным 0 и стандартным отклонением равным 1. В результате, распределение передвигается:
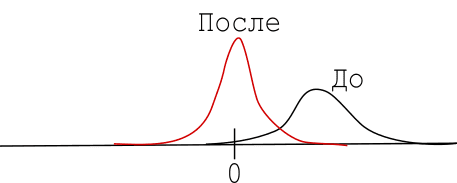
Для стандартизации данных в Scikit-learn есть класс StandardScaler, который применяет к каждому из атрибутов следующее: вычитает из значений среднее и делит полученную разность на стандартное отклонение. Проведем стандартизацию нескольких атрибутов:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X = data[['number_of_reviews','reviews_per_month']] X = scaler.fit_transform(X)
Таким образом, атрибуты number_of_review, reviews_per_month теперь выглядят так:
array([[-0.34284065, -0.57598766],
[ 5.54299242, 2.46242081],
[ 0.55920273, -0.44567217],
[-0.54580041, -0.72002056]])
Логарифмируем данные
Данные могут принимать очень широкий диапазон значений. Например, в нашем датасете минимальная цена равна $0, максимальная — $10000. Более того, если данные имеют асимметричное распределение (скошенное влево или вправо), тогда мы можем применить к ним логарифмирование. Зная свойство логарифмов:
сравним значения до логарифмирования и после:
log105 — log104 = 5 — 4 = 1
Как видим, после логарифмирования значения сравниваемы. В Python-библиотеке NumPy есть функция log, которая берет натуральный логарифм:import numpy as np
price = data.price y = np.log(price)
В результате имеем:
0 5.003946 3 4.488636 6 4.094345 12 4.488636 15 4.941642 Name: price, Length: 20104, dtype: float64
Сравните с истинными значениями цены:
0 149 3 89 6 60 12 89 15 140 Name: price, Length: 20104, dtype: int64
Заметим, логарифмирование применяется только к положительным числам.
Краткое резюме
Для повышения точности модели машинного обучения, а также ее корректной работы над исходными данными следует провести следующие операции:
- Перевести категориальные атрибуты в числовые.
- Удалить/Заполнить пустые Nanзначения.
- Стандартизировать/Нормализовать атрибуты.
- Логарифмировать атрибуты.
Делать все вышеперечисленное или что-то одно – зависит от исходного набора данных. Подробнее смотрите в видеообзоре, как выполнить подготовку данных и решить задачу регрессии:
В следующей статье поговорим о задаче регрессии и, в частности, о линейной регрессии. Как подготовить данные для реальных проектов Machine Learning вы узнаете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве: