Pandas — Python-библиотека обработки и анализа данных. Ее используют для чтения и манипулирования данными, упакованные в датасет. Датасет может быть представлен в формате csv, json, html, xlsx и т.д. Чаще всего используется csv — формат, в котором значения разделены запятой. Чтобы скачать библиотеку Pandas введите в командной строке:
pip install pandas
В качестве примера будем использовать датасет с олимпийскими играми, содержащий данные о спортсменах с 1896 по 2016 года. Скачать датасет можно на сайте Kaggle — площадки для соревнований по машинному обучению.
Анализ данных с Pandas
В основе Pandas лежит DataFrame. DataFrame — двумерное (табличное) представление данных. Один из способов создания DataFrame — чтение датасета, например в формате csv. Для начала импортируем библиотеку pandas и будем обращаться к ней как pd:
import pandas as pd
data = pd.read_csv('athlete_events.csv')
Метод read_csv читает датасет и возвращает DataFrame. Чтобы посмотреть первые пять строк вызываем метод head:
data.head()
Данные выглядят следующим образом:
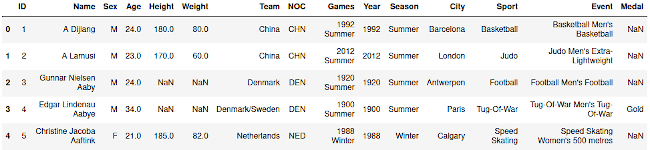
Считаем количество строк и столбцов
Как видно, здесь присутствуют пустые записи — NaN (c ними поработаем чуть позже). Чтобы посмотреть сколько всего строк и столбцов используем метод shape:
>>> data.shape (271116, 15)
Следовательно, в датасете 271.116 строк и 15 столбцов.
Для просмотра названий столбцов используем метод index:
>>> data.index Index(['ID', 'Name', 'Sex', 'Age', 'Height', 'Weight', 'Team', 'NOC', 'Games', 'Year', 'Season', 'City', 'Sport', 'Event', 'Medal'], dtype='object')
Извлекаем отдельные столбцы в Pandas
Из DataFrame можно извлекать отдельные столбцы. DataFrame имеет сходный синтаксис со словарем (dict), т.е. обращаться к значениям можно через квадратные скобки. Например, посмотрим на столбец Age:
>>> data['Age'] 0 24.0 1 23.0 2 24.0 3 34.0 4 21.0 ... 271111 29.0 271112 27.0 271113 27.0 271114 30.0 271115 34.0 Name: Age, Length: 271116, dtype: float64
Стоит заметить, что такое обращение к столбцу возвращает объект Series. Series — одномерное (столбчатое) представление данных. Можно сказать, что DataFrame представлен коллекцией Series.
Обращаться можно и к нескольким столбцам. Используя список (list) необходимых столбцов, можно получить новый датафрейм:
data[['Name', 'City', 'Sport']]
В результате получаем:
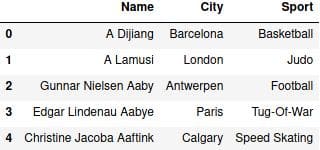
Name, City, Sport являются элементами списка. Для обращения используются квадратные скобки, так же как и с одним значением.
Извлекаем отдельные строки в Pandas
Извлечение строк также возможно с помощью метод iloc. Вот так выглядит обращение к одной строчке под номером 100:
>>> data.iloc[100] ID 36 Name Stefan Remco Aartsen Sex M Age 21 Height 194 Weight 78 Team Netherlands NOC NED Games 1996 Summer Year 1996 Season Summer City Atlanta Sport Swimming Event Swimming Men's 100 metres Butterfly Medal NaN Name: 100, dtype: object
Несколько строк извлекаем, устанавливая диапазон start и stop в методе iloc через двоеточие:
data.iloc[100:105]
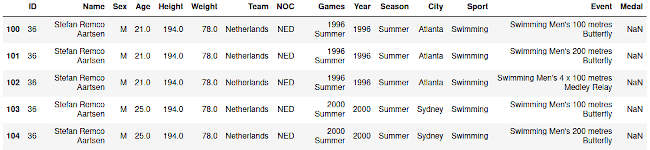
Извлекаем oтдельные строки и столбцы одновременно
Извлекаем строки и столбцы одновременно, соединяя оба метода:
data.iloc[100:105][['Name', 'City', 'Sport']]
Заметим также, порядок не извлечения не важен. Аналогично можно написать следующее:
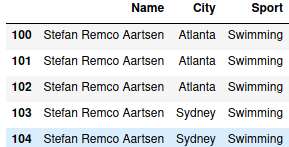
data[['Name', 'City', 'Sport']].iloc[100:105]
что приведет к тому же результату.
Описательная статистика и пустые значения
Для числовых значений можно получить описательную статистику методом describe:
data.describe()
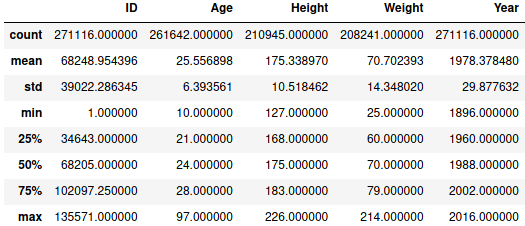
Пробежимся по атрибутам описательной статистики:
- сount обозначает количество записей,
- mean — среднее арифметическое,
- std — стандартное отклонение,
- min — минимальное значение,
- n-ый (25, 50, 75) % — n-ый квартиль,
- max — максимальное значение.
Строки с пустыми (NaN)значениями отбрасываются методом drop. У drop есть параметр subset, уточняющий, в каком столбце удалять; если его не указать, то отбросятся строки с NaN’ами каждого из столбцов. Удалим пустые значения Medal:
>>> data.dropna(subset=['Medal'])['Medal'] 3 Gold 37 Bronze 38 Bronze 40 Bronze 41 Bronze ... 271078 Silver 271080 Bronze 271082 Bronze 271102 Bronze 271103 Silver Name: Medal, Length: 39783, dtype: object
Как можно заметить, этот столбец имеет только 39.783 не NaN значений тогда, когда всего 271.116.
После всех манипуляций с данными не забудьте переприсвоить изменения. Вышеперечисленные методы создают новый DataFrame, а не изменяют старый. Например, чтобы в дальнейшем иметь дело с тремя столбцами, пишем:
data = data[['Name', 'City', 'Sport']]
Подведем итоги
read_csvсоздает DataFrame из датасета.- Метод
headвызывает 5 первых строк. - Атрибут
shapeпоказывает количество строк и столбцов. - Атрибут
indexвозвращает список названий столбцов. - Для извлечения столбца или столбцов указывается в квадратных скобках название столбца или список названий, соответственно.
- Метод
ilocвозвращает строки. - Метод
describeпоказывает описательную статистику. - Метод
dropотбрасывает пустые строки.
В нашей следующей статье мы познакомимся с 5 методами визуализации данных в matplotlib. На курсах по Python в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве вы узнаете о еще большем применении Pandas на практике.