
Временные ряды — это ключевой вид данных в финансовых, фармацевтических, медицинских и социологических отраслях. Анализ временных рядов не может обойтись без визуализации данных, и один график может заменить многостраничный отчет. Читайте далее, как строить базовые диаграммы, выстраивать сезонность, а также как группировать данные по разным промежуткам времени в рамках анализа временных рядов в Python
Формирование датасета
Мы воспользуемся датасетом с данными фондового рынка S&P 500. В этом датасете содержится 7 столбцов:
- Date — дата в формате yy-mm-dd.
- Open — цена акции при открытии рынка в долларах США.
- High — самая высокая цена за день.
- Low — самая низкая цена за день.
- Close — цена при закрытии.
- Volume — количество проданных акций.
- Name — тикер акции.
Для анализа временных рядов воспользуемся Python-библиотекой Pandas, а для визуализации данных — Matplotlib. Первым делом прочитаем датасет, где первым аргументом укажем ссылку на него. Кроме того необходимо правильно распарсить дату, для этого нужно указать в аргументе parse_dates флаг True, а также выведем её как столбец-индекс. Вот так выглядит чтение временных рядов в Python:
import pandas as pd url_data = "https://raw.githubusercontent.com/DataLatata/python-school/master/data/stock_data.csv" df = pd.read_csv(url_data, parse_dates=True, index_col="Date") df.head()
Open High Low Close Volume Name Date 2006-01-03 39.69 41.22 38.79 40.91 24232729 AABA 2006-01-04 41.22 41.90 40.77 40.97 20553479 AABA 2006-01-05 40.93 41.73 40.85 41.53 12829610 AABA 2006-01-06 42.88 43.57 42.80 43.21 29422828 AABA 2006-01-09 43.10 43.66 42.82 43.42 16268338 AABA
Базовые диаграммы
Мы можем воспользоваться встроенными в Pandas возможностями визуализации данных, о которых говорили тут. Например, следующий график в Python построит количество проданных акций в зависимости от даты:
df['Volume'].plot()
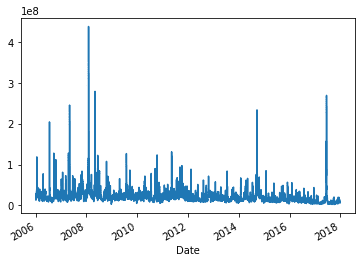
Это график выглядит довольно перегруженным. Хорошей идеей будет построить все остальные атрибуты в зависимости от даты. Для этого в методе нужно только указать subplots=True, поскольку дата является столбцом-индексом. Итак, визуализация временных рядов всех атрибутов в Python выглядит следующим образом:
df.plot(subplots=True, figsize=(10,12))
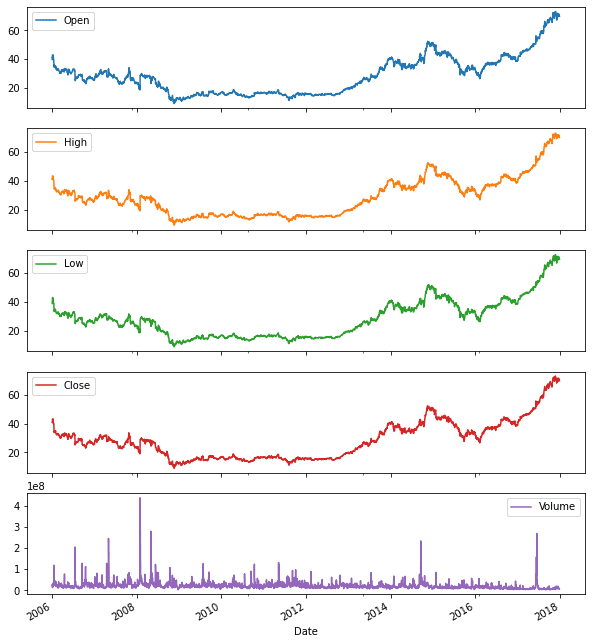
Из-за небольшого масштаба Open, High, Low и Close имеют малое различие друг перед другом.
Сезонность: что происходит в разные периоды времени
Линейные графики выше подходят для демонстрации сезонности. Так, мы можем узнать, что происходило с ценой в каждом месяце или году. Группировка данных в течение определенного периода времени и построение гистограмм — ещё один очень простой и широко используемый метод для определения сезонности временного ряда. Группировку даты можно выполнить с помощью метода resmaple, первым аргументом которого является правило группировки, например, день, 3 дня, месяц, год и т.д. [1]. Мы сгруппируем по месяцу и выберем среднее значение. Вот так выглядит группировка временных рядов, начиная с 2016 года, и последующая визуализация в Python:
import matplotlib.pyplot as plt
from matplotlib.dates import DateFormatter
# Группировка за месяц
df_month = df.resample("M").mean()
fig, ax = plt.subplots(figsize=(10, 6))
ax.xaxis.set_major_formatter(DateFormatter('%Y-%m'))
ax.bar(
df_month['2016':].index,
df_month.loc['2016':, "Volume"],
width=25, align='center')
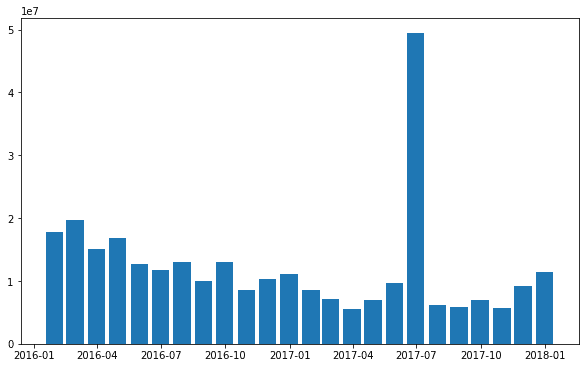
Обратите внимание, чтобы корректно отобразить дату на графике используется DateFormatter из библиотеки Matplotlib.
Диаграмма размаха для анализа сезонностим
Еще одним полезным инструментом анализа сезонности временных рядов является диаграмма размаха (boxplot). Она показывает диапазон значений, лежащих около среднего (чуть больше о ней тут). Для её построения можно воспользоваться ещё одной Python-библиотекой визуализации данных Seaborn.
Seaborn работает с DataFrame от Pandas. Добавим еще один столбец — месяц, чтобы указать его в функции boxplot. Пример кода на Python для построения диаграммы размаха в рамках анализа временных рядов:
import seaborn as sns
df['Month'] = df.index.month
fig, axes = plt.subplots(4, 1, figsize=(10, 16), sharex=True)
for name, ax in zip(['Open', 'Close', 'High', 'Low'], axes):
sns.boxplot(data=df['2016'], x='Month', y=name, ax=ax)
ax.set_ylabel("")
ax.set_title(name)
if ax != axes[-1]: # установить ось Х только для последнего
ax.set_xlabel('')
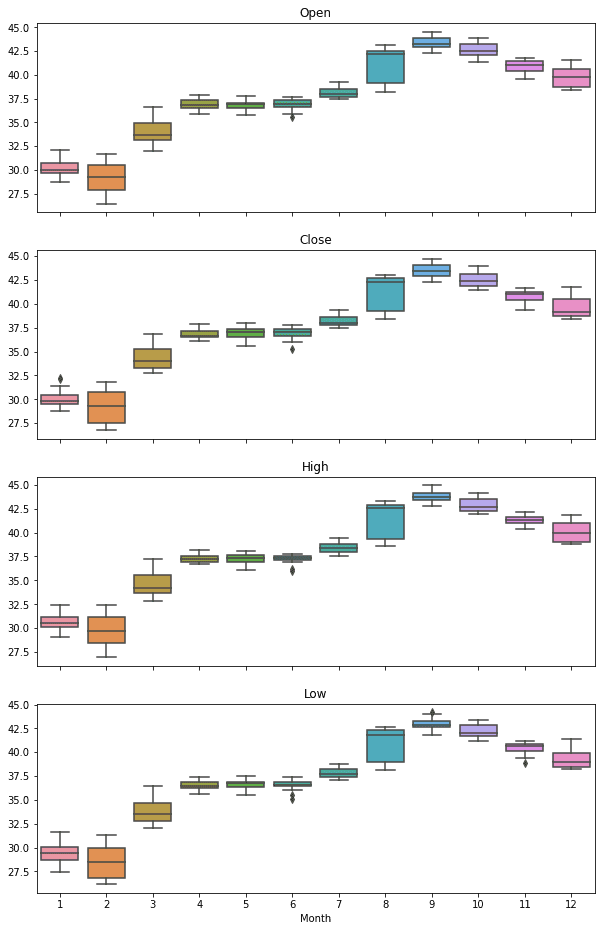
Можем видеть, как изменяется цена за акцию с течением времени, что собственно можно наблюдать на фондовых биржах.
Разное время, один график
Самый первый график с зависимостью Volume от даты слишком нагружен, поэтому его сложно интерпретировать. Мы можем снова сгруппировать данные за месяц и взять среднее. Группировка (resampling) позволяет рассматривать результаты временных рядов в разных масштабах, наблюдая тренды в разные периоды времени.
К тому же тренды за разные периоды времени можно строить на одном графике. Например, построим графики за с ежедневными и недельными отчетами на закрытие (Open) за 2015 год. Код на Python для визуализации ежедневного и недельного графика:
df_week = df.resample("W").mean()
start, end = '2015-01', '2015-08'
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(df.loc[start:end, 'Volume'],
marker='.', linestyle='-',
linewidth = 0.5, label='Daily',
color='black')
ax.plot(df_week.loc[start:end, 'Volume'],
marker='o', markersize=8,
linestyle='-', label='Weekly',
color='coral')
ax.set_ylabel("Open")
ax.legend()
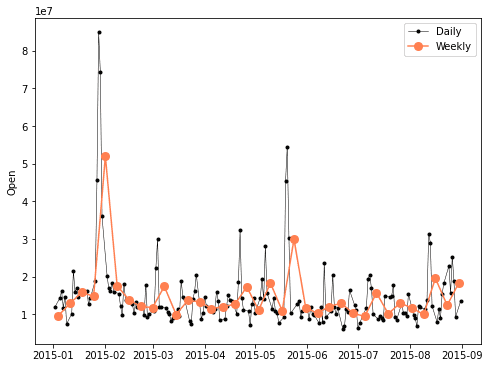
Чем выше частота, тем больше появляется взлетов и падений, и наоборот, чем ниже частота, тем тренд становится более глаже. Месячный отчет был бы ещё плавнее, чем недельный.
Больше подробностей об анализе временных рядов и подготовке данных на примерах прикладных задач Data Science на языке Python вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации Data Scientist’ов и IT-специалистов в Москве.

