Kaggle – это одна из самых популярных онлайн-площадок для соревнований по машинному обучению. Здесь разные компании публикуют бизнес-задачу, которую участники должны решить с помощью методов Machine Learning. Организатор предоставляет датасет по проблеме и выдают победителям денежный приз, размер которого может достигать 1 миллиона долларов [1].
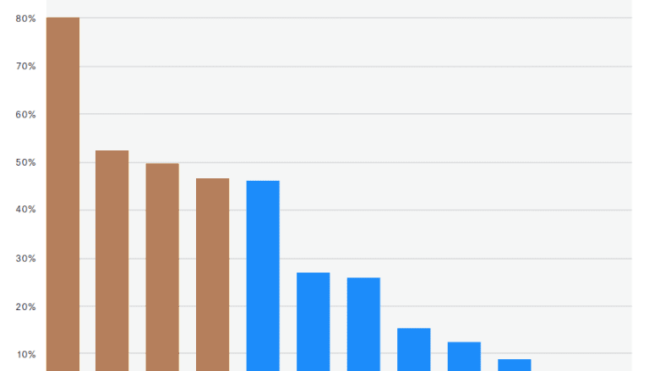
Каждый год Kaggle публикует исследования об участниках соревнований, например, их образование, пол, используемый язык программирования, библиотеки и прочие нюансы. В этой статье мы расскажем о 4 наиболее используемых библиотеках Machine Learning согласно исследованиям, проведенными Kaggle 7 месяцев назад [2].
1. Scikit-learn
Это библиотека стоит на первом месте в списке инструментов, которые используют участники Kaggle. Scikit-learn – одна из самых больших и разнообразных библиотек, предоставляющая разнообразные средства машинного обучения: алгоритмы классификации, регрессии, кластеризации, уменьшения размерности, настройка параметров, подготовка данных, методы композиции, небольшие датасеты, метрики и т.д. Одних только алгоритмов классификации насчитывается 41, регрессии — 95, а кластеризации – 105 разновидностей. Scikit-learn использует массивы NumPy, что ускоряет работу алгоритмов. Почему NumPy такой быстрый, подробнее об этом мы рассказывали здесь. Из недостатков можно отметить акцент на классических алгоритмах Machine Learning – методы глубокого обучения здесь практически не реализованы.
2. Keras
Keras – высокоуровневая библиотека глубокого обучения для Python. Основное применение — конструирование архитектуры нейронных сетей: полносвязных, рекуррентных, сверточных и т.д. Keras не занимается работой с тензорами, поэтому здесь поддерживаются библиотеки TensorFlow, Theano, Microsoft Cognitive Toolkit (CNTK) [3, 4]. Помимо этого, Keras позволяет работать с CPU и GPU. Если требуется построить сложную сетевую архитектуру с множественными слоями и моделями, то Keras будет незаменимым инструментом.
3. XGBoost
Библиотека XGBoost обеспечивает работу алгоритмов градиентного бустинга для языков программирования Python, C++, R, Java, Julia, Scala. До волны глубокого обучения здесь в основном использовались ядерные методы и случайные леса. В 2014 году начал распространяться метод градиентного бустинга [5]. Его считали «святым Граалем» соревнований по машинному обучению. Были выиграны соревнований сего помощью [6]. Тогда же появилась библиотека XGBoost, реализующая деревья решений (decision tree) с использованием градиентного бустинга.
Позже методы глубокого обучения сместили градиентный бустинг с 1-го места. XGBoost поддерживает так называемые параллельные деревья бустинга: GBDT и GBM, которые до сих пор активно используются Data Scientist’ам для решения многих задач. Например, данная библиотека предоставляет такие особенности, как:
- Распараллеливание построения деревьев с использованием всех ядер CPU во время обучения (GPU тоже поддерживается).
- Распределенные вычисления для обучения больших моделей с использованием машин кластеров.
- Внеядерные вычисления для больших наборов данных, которые не помещаются в оперативную память.
- Оптимизированное использование кэширования [7, 8].
4. TensorFlow
Разработанная под руководством Google Brain, библиотека TensorFlow позволяет работать с тензорами и конструировать нейронные сети. Раньше она использовалась в связке с Keras, но начиная с версии 2.0, в TensorFlow был добавлен модуль tf.keras. Планируется, что уже в ближайшем будущем он полностью заменит Keras. Об этом написал в сенятбре 2019 года сам создатель Keras — Франсуа Шолле [9]. Поэтому с переходом разработчиков на TensorFlow 2.0 не придется явно работать с Keras, если не требуется Theano или CNTK. На сегодня TensorFlow – это не отдельная библиотека, а целый комплексный фреймворк машинного обучения.
В следующей статье мы поговорим об использовании Python для математиков. А как на практике использовать все эти и другие Python-библиотеки в Big Data, Machine Learning и других проектах Data Science, вы узнаете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
- https://www.kaggle.com/c/data-science-bowl-2017/overview/prizes
- https://www.kaggle.com/kaggle-survey-2019
- https://keras.io/api/utils/backend_utils/
- https://keras.io/why_keras/
- https://www.analyticsvidhya.com/blog/2018/09/an-end-to-end-guide-to-understand-the-math-behind-xgboost/
- https://github.com/dmlc/xgboost/tree/master/demo#machine-learning-challenge-winning-solutions
- https://xgboost.readthedocs.io/en/latest/build.html#building-xgboost-from-source
- https://machinelearningmastery.com/gentle-introduction-xgboost-applied-machine-learning/
- https://twitter.com/fchollet/status/1174018651449544704?lang=en