Pandas — полезный инструмент Data Science, но некоторые его методы для обработки данных требуют слишком много времени. Поэтому сегодня мы расскажем, как ускорить Pandas в сотни раз с помощью всего лишь двух функций NumPy — where и select.
Векторизация NumPy
Частой задачей Data Scientist’a при работе с данными является фильтрация этих самых данных, например, разбиение на категории, выбор определенных значений и т.д. Для этого могут использоваться методы Pandas, такие как apply и iterrows. Их минусом является применение циклов, когда Python проходится по каждой строке или столбцу, а это ресурсоёмкий процесс. Хотя для метода apply не нужно прописывать циклы вручную, Pandas сам их использует в своем исходном коде. В зависимости от размера данных и характеристик вычислительных устройств на обработку может уйти драгоценное время, которое лучше потратить на что-то полезное. Чтобы избежать этой проблемы, рекомендуется прибегнуть к векторизации с помощью NumPy.
Векторизация в NumPy не использует явных циклов, индексации и т. д. В коде эти вещи происходят «за кулисами» в оптимизированном, предварительно скомпилированном коде C. Именно этими особенностями мы и воспользуемся, чтобы сократить обработку данных до миллисекунд. В частности, прибегнем к использованию функций where и select.
Датасет и средство измерения
В качестве данных для анализа возьмем датасет из Kaggle, который содержит информацию о домах на продажу в Бруклине и доступен для скачивания. Датасет содержит более 300.000 записей (строк) и 111 атрибутов (столбцов).
Все вычисления происходили в Google Colab, а средством измерения времени — магическая команда %%timeit, о которой говорили тут.
Прежде всего импортируем Python-библиотеки Pandas и NumPy и инициализируем DataFrame:
import pandas as pd
import numpy as np
df = pd.read_csv('brooklyn_sales_map.csv')
Пример разделения на категории
Допустим, требуется разделить данные на 2 категории. В нашем датасете есть атрибут налоговый класс (tax class). Всего имеется 5 налоговых классов, а мы разобьём их на 2: те, которые принадлежат 1-му, и все остальные. Ниже пример того, как это делается в Python без векторизации с помощью метода apply. Такой процесс обработки датасета в Colab занял 7.13 секунд.
def check_tax_class(row):
if row['tax_class'] == '1':
return 1
else:
return 2
df['new_group'] = df.apply(check_tax_class, axis=1)
Решение в NumPy. А вот векторизация NumPy займет гораздо меньше времени. Когда у вас есть 1 условие и два выбора (одно от if, другое от else), то используйте функцию NumPy — where:
df['new_group'] = np.where(
df['tax_class'] == '1',
1,
2
)
Функция where принимает первым аргументом условие, вторым — результат выполнения условия, третьим — результат невыполнения условия. Несмотря на то, что этот код делает то же самое, что мы определили для apply, время выполнения равно 22.6 миллисекунд. Таким образом, мы ускорили обработку данных в 315 раз.
Когда условий больше, чем одно
Если условий больше, чем одно, то функция для apply не сильно изменится, появится только цепочка if-elif-else. Например, требуется найти подходящее жилье с учётом соседних регионов. Python-код ниже демонстрирует подобное выражение, где имеется множество условий. В итоге, метод apply занял 17.6 секунд.
list1 = ['WINDSOR TERRACE', 'WYCKOFF HEIGHTS', 'BATH BEACH']
list2 = ['CYPRESS HILLS', 'EAST NEW YORK', 'GOWANUS']
def serach_for_great_place(row):
if row['year_built'] > 2000:
return 'New built'
elif row['neighborhood'].startswith('WILLIAMSBURG'):
return 'Old WILLIAMSBURG'
elif row['neighborhood'] in list1:
return 'Good place'
elif row['neighborhood'] in list2:
return 'Nice place'
else:
return 'Not satisfied'
df['new_group'] = df.apply(serach_for_great_place, axis=1)
Решение в NumPy. Когда у вас есть цепочка условий, используйте функцию NumPy — select. Она принимает на вход три аргумента:
- список условий,
- список возвращаемых значений,
- значение по умолчанию (то, что стоит в else).
Тогда код выше можно переписать следующим образом:
conditions = [
df['year_built'] > 2000,
df['neighborhood'].str.startswith('WILLIAMSBURG'),
df['neighborhood'].isin(list1),
df['neighborhood'].isin(list2)
]
choices = [
'New built',
'Old WILLIAMSBURG',
'Good place',
'Nice place'
]
df['new_group'] = np.select(conditions, choices, default='Not satisfied')
С векторизацией мы получили тот же результат, что и apply, но за 163 миллисекунды. Таким образом, мы смогли ускорить Pandas в 124 раза.
Вложенные условия
Иногда внутри условия может стоять ещё дополнительные условия. Например, ниже код в Python показывает вложенные условия в применяемой функции. Выполнение заняло 15 секунд.
def serach_for_great_place(row):
if row['year_built'] > 2000:
if row['sale_price'] < 200000:
return 'New built (cheap)'
elif row['sale_price'] < 550000:
return '(medium)'
else:
return '(expensive)'
elif row['neighborhood'] in list1:
return 'Good place'
elif row['neighborhood'] in list2:
return 'Nice place'
else:
return 'Not satisfied'
df['new_group'] = df.apply(serach_for_great_place, axis=1)
Решение в NumPy. Поскольку вложенность подразумевает выполнение одновременно нескольких условий, то мы просто можем добавить амперсанд & между такими условиями в select. Это выглядит следующим образом:
conditions = [
((df['year_built'] > 2000) & (df['sale_price'] < 200000)), # выполняются оба
((df['year_built'] > 2000) & (df['sale_price'] < 550000)),
df['year_built'] > 2000,
df['neighborhood'].isin(list1),
df['neighborhood'].isin(list2)
]
choices = [
'New built (cheap)',
'New built (medium)',
'New built (expensive)',
'Good place',
'Nice place'
]
df['new_group'] = np.select(conditions, choices, default='Not satisfied')
Этот код занял 56.2 миллисекунды. Итак, Pandas смог ускориться с помощью NumPy в 267 раз.
Ускоряем обработку данных еще в 600 раз
Допустим, требуется определить те дома, которые имеют одинаковый налоговый класс и разницу в дате продажи (sale date) не более чем в 3 года. Прежде всего нужно распарсить атрибут дата продажи, поскольку он воспринимается как строковое значение (str), а не дата. Для этого сделаем следующее:
parser = lambda date: pd.datetime.strptime(date, '%Y-%m-%d')
df = pd.read_csv('brooklyn_sales_map.csv',
date_parser=parser, parse_dates=['sale_date'])
Теперь воспользуемся методом iterrows, который пройдется по каждой строке, и будем добавлять в результирующий список 0, если условие выполняется, и 1 в противном случае. Ниже приведена реализация в Python. Разность между датами измеряется в днях, поэтому мы умножаем на 365. В итоге, такая обработка заняла 1 минуту и 7 секунд, что довольно много.
from datetime import timedelta
def check_dates(df):
result = []
for i, row in df.iterrows():
if i > 0:
if df.loc[i, 'tax_class'] == df.loc[i-1, 'tax_class']:
t1 = df.loc[i-1, 'sale_date']
t2 = df.loc[i, 'sale_date']
if t1 - t2 > timedelta(3*365):
result.append(0)
else:
result.append(1)
else:
result.append(1)
else:
result.append(np.nan)
return result
a = check_dates(df)
Решение в NumPy. Мы сначала сдвинем соответствующие атрибуты на 1 строчку с помощью метода shift так, как это показано на рисунке. А затем просто применим функцию select с вложенными условиями.
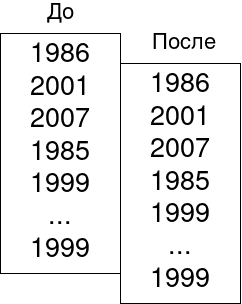
prev_tax_class = df['tax_class'].shift(1).fillna(np.nan)
prev_sale_date = df['sale_date'].shift(1).fillna(pd.Timestamp('1900'))
conditions = [
((df['tax_class'].values == prev_tax_class) &
(prev_sale_date - df['sale_date'] > timedelta(3*365))),
df['tax_class'].values == prev_tax_class
]
choices = [0, 1]
b = np.select(conditions, choices, default=1)
Такая реализация заняла 98.5 миллисекунд. И мы смогли ускорить Pandas в 670 раз! Причем мы выиграли не только в скорости выполнения, но и улучшили читаемость кода.
Освоить другие полезные приемы повышения производительности при анализе больших данных на реальных проектах Data Science с примерами вы сможете на наших практических курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.

