При работе с таблицами Pandas порой приходится их видоизменять, в частности, когда таблица многоуровневая. В этой статье мы расскажем вам об основных функциях Pandas для изменения формы таблицы. К этим функциям относятся: pivot для создания сводной таблицы, stack/unstack для добавления/удаления уровня и melt для преобразования столбцов в строки.
Сводные таблицы с Pivot
Индекс — это то, чем маркируются строки (по умолчанию это просто 1, 2,…n). Чтобы в таблице задать новый столбец с другими значениями индексов, используйте в Pandas метод pivot. Для изменения формы указываются аргументы: index (индекс), columns (столбцы), values (значения). Вам может понадобится pivot тогда, когда нужно зафиксировать новый индекс с новым столбцом.
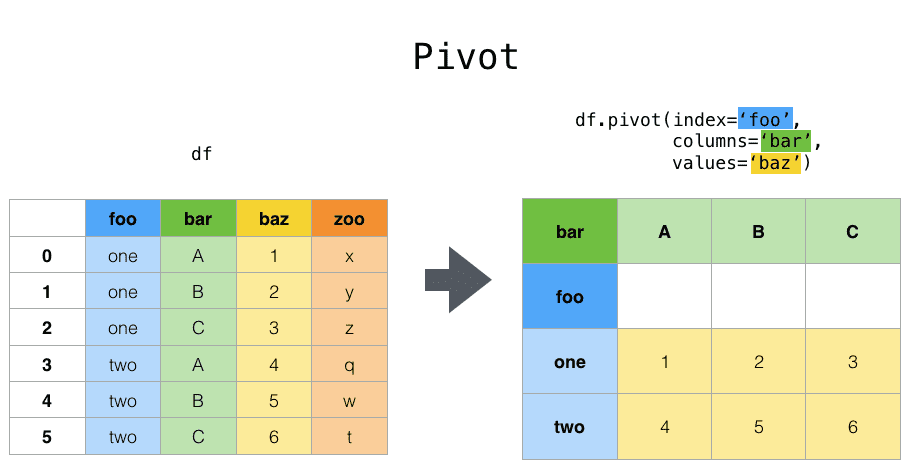
Пример с кодом на Python для создания сводной таблицы:
import pandas as pd
data = [
['one', 1., 2, 'x'],
['two', 4., 5, 'y'],
['six', 5., 3, 'z'],
['one', 6., 5, 'w'],
]
cols = ['foo', 'bar', 'buz', 'fee']
df = pd.DataFrame(data, columns=cols)
df.pivot(
index='foo',
columns='bar',
values='buz'
)
bar 1.0 4.0 5.0 6.0 foo one 2.0 NaN NaN 5.0 six NaN NaN 3.0 NaN two NaN 5.0 NaN NaN
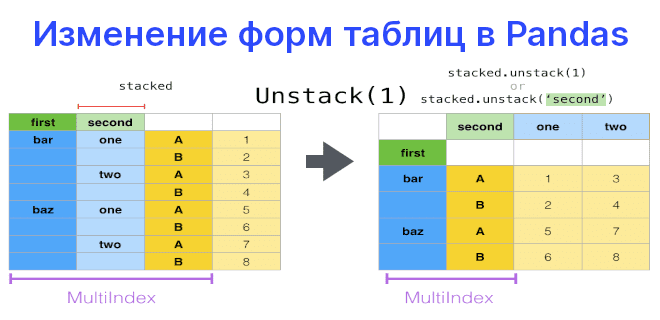
Добавляем и удаляем уровни
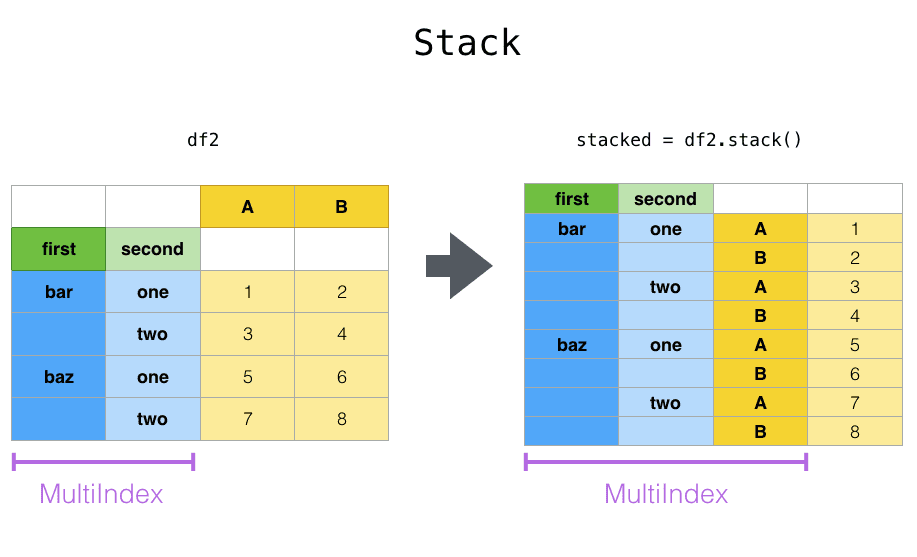
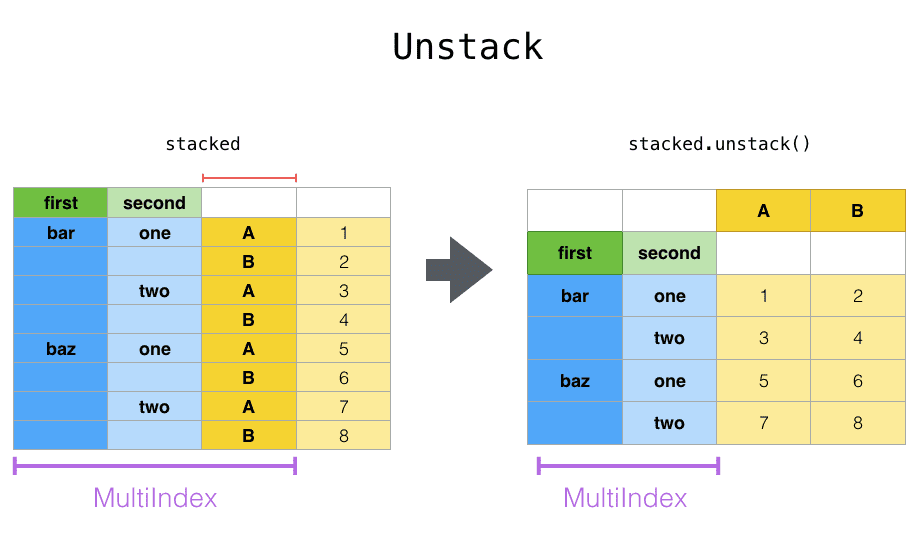
С pivot тесно связаны связанные методы stack и unstack как для объектов Series, так и DataFrame. Эти методы предназначены для совместной работы с многоуровневыми таблицами. Под уровнем подразумевается столбец в индексе. Вот что в сущности делают эти методы:
stackдобавляет новый уровень к индексу из столбцаunstackделает противоположное — избавляется от уровня и добавляет его к столбцам
На практике для облегчения работы с таблицами приходится избавляться от уровней, т.е. использовать unstack.
Код на Python для добавления уровня в таблице Pandas:
# DataFrame тот же, что и выше df.stack()
0 foo one bar 1 buz 2 fee x 1 foo two bar 4 buz 5 fee y 2 foo two bar 5 buz 3 fee z 3 foo one bar 6 buz 5 fee w dtype: object
Из столбцов в переменные
Функция melt или метод DataFrame.melt предназначены для преобразования одного или более столбцов в строки с измеряемыми значениями. По умолчанию новый столбец с полученными строками имеет название variable, а столбец с измеряемыми значениями — value. Эти названия могут быть изменены параметрами var_name и value_name.
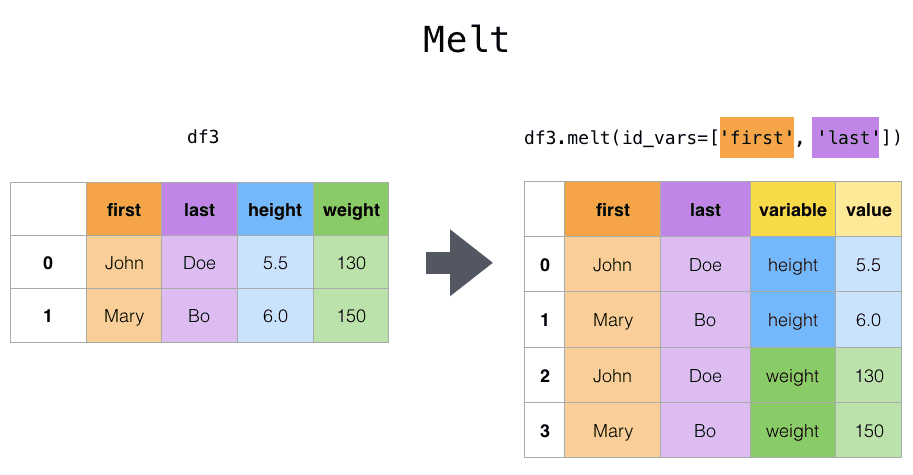
Следующий пример на Python демонстрирует результат Pandas-функции melt:
# DataFrame тот же, что и выше
df.melt('foo')
foo variable value 0 one bar 1 1 two bar 4 2 two bar 5 3 one bar 6 4 one buz 2 5 two buz 5 6 two buz 3 7 one buz 5 8 one fee x 9 two fee y 10 two fee z 11 one fee w
Еще больше подробностей о преобразовании таблиц Pandas в рамках анализа данных и задач Data Science на реальных примерах вы узнаете на нашем специализированном курсе «DPREP: Подготовка данных для Data Mining на Python» в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.

