В предыдущей статье мы реализовали функцию в Python для нахождения раковых клеток. Сегодня на примере этой функции расскажем о 5 методах обработки множества изображений с помощью списковых включений и многопроцессорной обработки (multiprocessing) в Python.
Функция обнаружения раковых клеток
Прежде чем приступить к перечислению способов обработки изображений в Python, напомним о созданной в прошлый раз функции для нахождения координат клеток (точнее их центров):
from skimage.filters import gaussian
from skimage.feature import peak_local_max
def detect_nuclei(img, sigma=4, min_distance=6, threshold_abs=1000):
g = gaussian(img, sigma, preserve_range=True)
return peak_local_max(g, min_distance, threshold_abs)
Эту функция работает только для одного изображения. Поэтому тут возникает вопрос, как применить ее для всех изображений. Следующие 5 способов демонстрируют разные подходы, но некоторые из них быстрее, некоторые медленнее. Тестировать их работу мы будем в Google Colab, замерять время с помощью магической команды %%timeit (о них больше тут).
Метод #1 Списковые включения с skimage.io
Списковое включение (list comprehension) — элегенатный способ создания списков в Python (о нем говорили тут). Им и воспользуемся.
Применим списковое включение для функции detect_nuclei Для чтения изображений воспользуемся функцией io.imread из Python-библиотеки skimage.
Пример функции Python по созданию спискового включения, которое хранит изображения с координатами клеток, с найденными раковыми клетками:
from skimage import io
def process_images1(paths):
return [detect_nuclei(io.imread(p)) for p in paths]
Теперь вызовем ее:
%timeit -n 4 -r 1 centers = process_images1(paths) # => 4 loops, best of 1: 26.6 s per loop
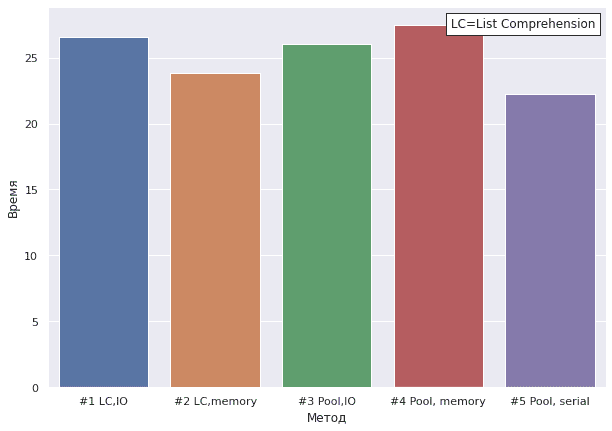
Среднее время из 4 повторений составило 26.6 секунд.
Метод #2 Списковые включения из памяти
Что произойдет, если перед вызовом detect_nuclei мы сохраним все изображения в память, например, сохраним их в массивы NumPy, а затем применим списковые включения?
Код на Python для создания NumPy-массивов из изображений с последующим сохранением результатов в списке выглядит следующим образом:
import numpy as np
images = np.asarray([io.imread(p) for p in paths])
def process_images3(images):
return [detect_nuclei(img) for img in images]
centers = process_images3(images)
# => 4 loops, best of 1: 26 s per loop
Как можем заметить, этот метод оказался не настолько быстрее, чем предыдущий (разница в 0.6 сек).
Метод #3 Многопроцессорная обработка с skimage.io
Для многопроцессорной обработки в Python используется стандартный пакет multiprocessing.
Сперва нам нужно определить функцию, которая объединит detect_nuclei и io.imread. Так, мы можем отдать их исполнение pool.map, которая уже сама распределит вычисления по тредам.
Реализация многопроцессорной обработки в Python:
import multiprocessing as mp
def _process_image(path):
return detect_nuclei(io.imread(path))
def process_images2(paths):
with mp.Pool() as pool:
return pool.map(_process_image, paths)
centers = process_images2(paths)
# => 4 loops, best of 1: 23.9 s per loop
Этот метод оказался чуть быстрее, чем предыдущий (разница 2.1 сек). На машинах с большим количеством ядер, результат будет еще лучше.
Метод #4 Многопроцессорная обработка с чтением из памяти
Попробуем применить многопроцессорную обработку с изображениями сохраненными в виде массивов NumPy, т.е. выполним чтение из памяти:
images = np.asarray([io.imread(p) for p in paths])
def process_images4(images):
with mp.Pool() as pool:
return pool.map(detect_nuclei, images)
centers = process_images4(images)
# => loops, best of 1: 27.5 s per loop
Этот метод оказался самым медленным. Согласно документации данные, посылаемые рабочему процессу данные предварительно должны быть сериализованы через pickle [1]. Однако сериализация затрагивает лишние вычисления, и по итогу вычисления будут производиться еще дольше. Но это можно обойти (см. метод #5)
Метод #5 Многопроцессорная обработка с сериализацией
Есть несколько путей избежать накладных расходов на сериализацию при использования multiprocessing. В Unix-системах большие массивы обрабатываются в памяти довольно эффективно. Возможно, этот метод не сработает на Windows
Unix-системы используют процедуру копирования при записи (copy-on-write) для разветвленных процессов. Копирование при записи означает, что разветвленный процесс будет копировать данные только при попытке изменить общую виртуальную память. Все это, конечно, происходит за кулисами. Но именно этой особенностью можно воспользоваться:
def _process_image_memory_fix(i):
global images
return detect_nuclei(images[i])
def process_images5(n):
with mp.Pool() as pool:
return pool.map(_process_image_memory_fix, range(n))
centers = process_images5(len(paths))
# => loops, best of 1: 22.3 s per loop
Вот мы и выявили победителя сегодняшнего конкурса. Заметим, что в функции мы определили массив изображений в глобальной области видимости. Это шаг не обязателен, но массив должен быть инициализирован. Затем мы сопоставляем все индексы и позволяем каждому процессу получить доступ к необходимому изображению путем индексации в массиве изображений. Этот подход будет обрабатывать только целые числа, а не сами изображения.
Ниже показаны результаты времени вычислений каждого из метода. Поскольку разница получилась не очень большая, дадим общую рекомендацию: если у вас много ядер используйте многопроцессорную обработку Python (если еще и Unix, то метод #5), а при небольшом количестве ядер, применяйте списковые включения, предварительно сохранив в виде массива изображения (метод #2).
Еще больше подробностей о обработке изображений на реальных задачах Data Science вы узнаете на специализированном курсе по компьютерному зрению «VISI: Computer vision на Python» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.
Источники

