
Среды Jupyter используются практически каждым Data Scientist’ом. Возможность “на лету” работать с данными и получать мгновенный результат является несомненным преимуществом Jupyter. Но при работе над крупными проектами совместная разработка немного усложняется. Было бы плюсом иметь возможность проведения совместной разработки в реальном времени. При этом хотелось бы, чтобы это было асинхронном режиме, поскольку члены команды могут работать в разное время над одним и тем же проектом. И вот на сцене появляется Ploomber. В этой статье мы расскажем вам, что такое Ploomber и зачем он вам нужен.
Что такое Ploomber
Ploomber — это менеджер сборки блокнотов Jupyter (ipynb). Он позволяет переводить файлы Python с расширением py в ipynb и обратно, тем самым упрощая совместную работу над одним проектом. Рассмотрим далее, какие полезные возможности он представляет.
Поддержка Git
Управлять файлами ipynb внутри команды нелегко. Одно дело, когда ты один работаешь в блокноте: пишешь скрипты, анализируешь данные — а другое, когда подсоединяется кто-то ещё, ведь эти блокноты представляют собой файлы JSON.
Допустим, вы пушите ipynb-файл в репозиторий git. Затем добавляете ячейку с обычным комментарием. После выполнения коммита и просмотра изменений в файле, видим такое:
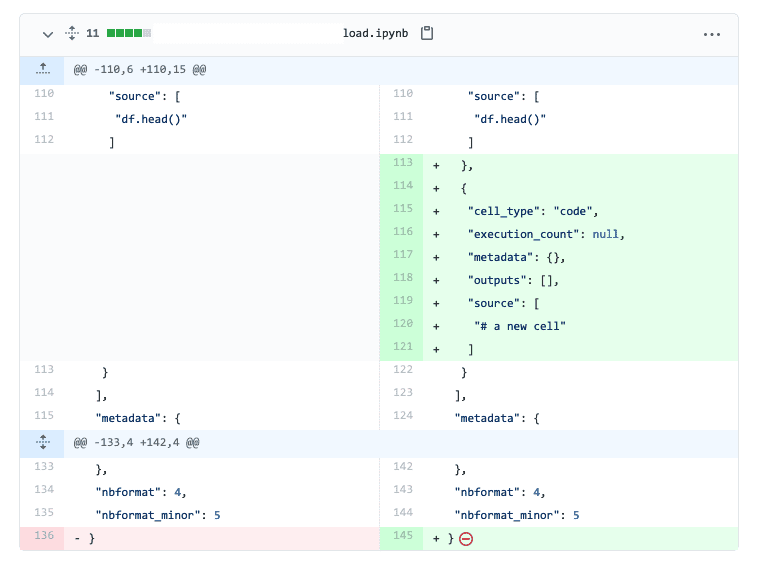
Подобное очень сложно разобрать. Проверять изменения в таком файле неудобно, отсюда, сложность проведения обзора кода (code review). Но для этой цели мы можем поменять формат файла. Так, например, Jupytext позволяет открывать файлы формата .py и .md в виде блокнотов. Именно он встроен в Ploomber. Таким образом, работаете вы в блокноте, а передаете файлы Python, и через них же и взаимодействуете с членами команды.
Поддержка модульности
В большинстве случаев приходится работать в одном блокноте. Действительно, разбивая на отдельные файлы свои скрипты, мы вынуждены следить за структурой проекта и запускать блокноты в правильном порядке. Ploombler позволяет объединять множество блокнотов в единый конвейер. Это делается в два шага:
- Перечисление блокнотов в файле YAML (Yet Another Markup Language).
- Объявление зависимостей выполнения.
Ploomber определяет все зависимости выполнения и сам внедряет нужные ячейки в блокнот после его открытия. На рисунке ниже показано, как создать конвейер через файл pipeline.yaml и как внедряется ячейка в блокнот.
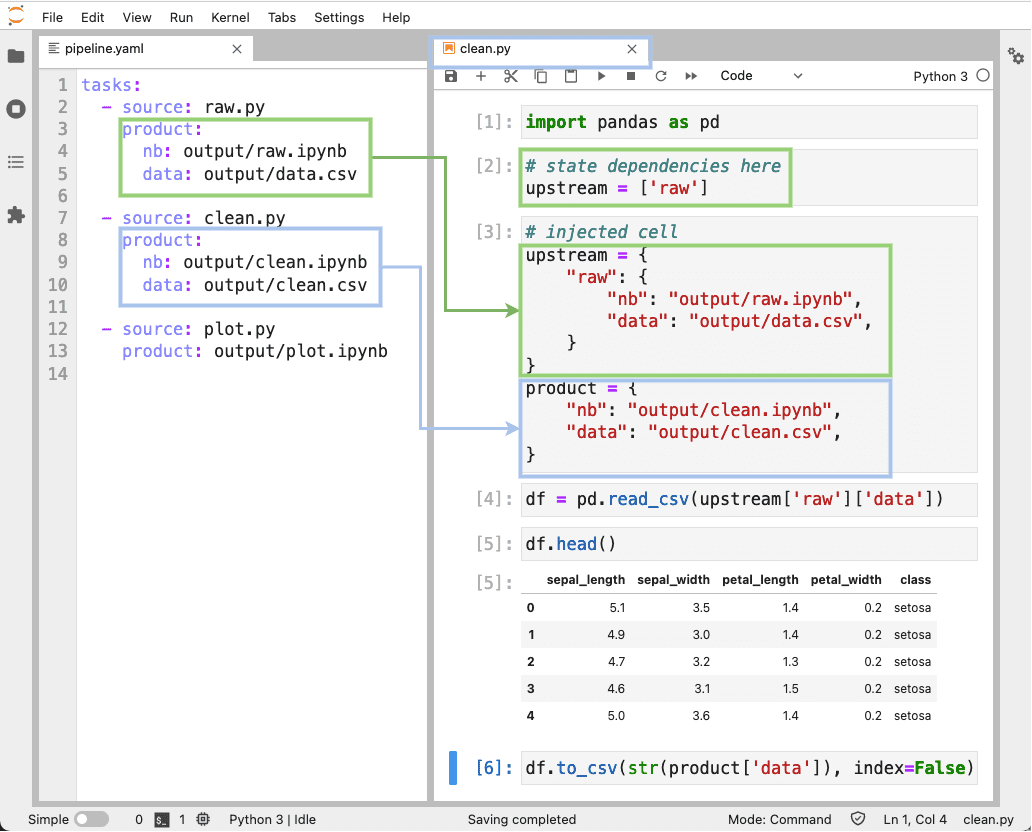
Принцип модульности помогает команде совместно работать в разных ветках. Например, команда из двух человек работает над проектом с разными данными, которые затем нужно объединить в единый обучающий датасет, тогда процесс разработки может быть следующим:

Поддержка тестирования
Разбиение на модули делает удобным тестирование (о нем говорили тут). Обычно проверяют выходные данные на соответствие ожидаемому качеству. А поскольку всё разбито на модули, то Ploomber позволяет проводить тестирование для каждой задачи.
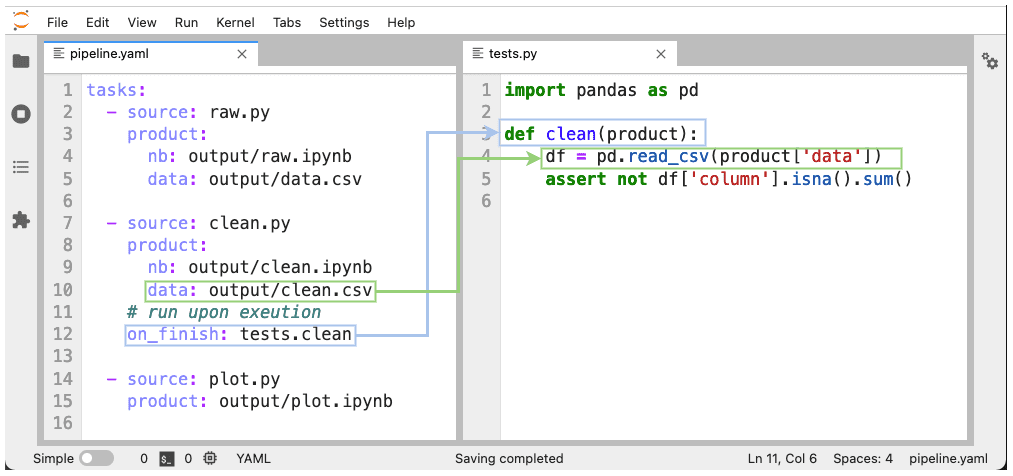
В Ploomber можно выполнять заданную функцию для проверки выполнения условий, как это показано на рисунке ниже.
Поддержка воспроизводимости
В мире Data Science проводить тестирование неудобно из-за больших данных (Big Data). Ведь тестирование модели машинного обучения (Machine Learning) может занимать часы, а то и больше. Такая проблема решается предварительным прогоном модели на малом количестве данных. Так вот в Ploomber это реализуется через параметр sample для того, чтобы запустить конвейер только на некоторой части входных данных. Тогда будет обеспечена непрерывная интеграция (continuous integration, CI).
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
11 августа, 2025
Продолжительность
24 ак.часов
Стоимость обучения
54 000 руб.
Поддержка внесения кода (Pull request)
Как только модуль был протестирован, команда может приступать к внесению собственного кода в проект с помощью pull request. А поскольку весь код находится в файле py, а не в ipynb, то сразу становится понятно, что и где в коде поменялось.
С другой стороны, код все равно должен быть проверен, а проще это сделать в самом Jupyter Notebook. Поэтому Ploomber генерирует файлы формата ipynb для каждого файла формата py.
Такой CI-процесс можно организовать с помощью команды: ploomber build. А при работе с большими наборами данных Ploomber может экспортировать конвейеры данных в AWS Batch, Airflow или Kubernetes (Argo Workflows).
Поддержка быстрого итерирования
Перезапускать весь конвейер ради найденной ошибки в одном из модулей, пустая трата времени. Поэтому для поддержки быстрого итерирования Ploomber строит конвейеры постепенно, пропуская те модули, чей код не изменился. Поэтому если на каком-то этапе была найден ошибка, устраните её и начните выполнения ровно с этого места.
О подготовке данных и построении конвейеров Machine Learning на реальных примерах с помощью языка Python вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.
- FUNP: Основы языка Python для анализа данных и решения задач машинного обучения
- DPREP: Подготовка данных для Data Mining на Python
- PYML: Машинное обучение на Python

