
Хотя многие Data Scientist’ы больше привыкли работать с CSV-файлами, на практике очень часто приходится сталкиваться с обычными Excel-таблицами. Поэтому сегодня мы расскажем, как читать Excel-файлы в Pandas, а также рассмотрим основные возможности Python-библиотеки OpenPyXL для чтения метаданных ячеек.
Дополнительные зависимости для возможности чтения Excel таблиц
Для чтения таблиц Excel в Pandas требуются дополнительные зависимости:
- xlrd поддерживает старые и новые форматы MS Excel [1];
- OpenPyXL поддерживает новые форматы MS Excel (.xlsx) [2];
- ODFpy поддерживает свободные форматы OpenDocument (.odf, .ods и .odt) [3];
- pyxlsb поддерживает бинарные MS Excel файлы (формат .xlsb) [4].
Мы рекомендуем установить только OpenPyXL, поскольку он нам пригодится в дальнейшем. Для этого в командной строке прописывается следующая операция:
pip install openpyxl
Затем в Pandas нужно указать путь к Excel-файлу и одну из установленных зависимостей. Python-код выглядит следующим образом:
import pandas as pd
pd.read_excel(io='temp1.xlsx', engine='openpyxl')
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
Читаем несколько листов
Excel-файл может содержать несколько листов. В Pandas, чтобы прочитать конкретный лист, в аргументе нужно указать sheet_name. Можно указать список названий листов, тогда Pandas вернет словарь (dict) с объектами DataFrame:
dfs = pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
sheet_name=['Sheet1', 'Sheet2'])
dfs
#
{'Sheet1': Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64,
'Sheet2': Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78}
Если таблицы в словаре имеют одинаковые атрибуты, то их можно объединить в один DataFrame. В Python это выглядит так:
pd.concat(dfs).reset_index(drop=True)
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
3 Gosha 43 95
4 Anna 24 65
5 Lena 22 78
Указание диапазонов
Таблицы могут размещаться не в самом начале, а как, например, на рисунке ниже. Как видим, таблица располагается в диапазоне A:F.
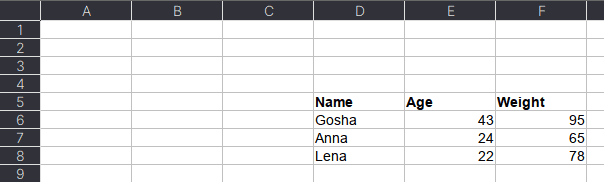
Чтобы прочитать такую таблицу, нужно указать диапазон в аргументе usecols. Также дополнительно можно добавить header — номер заголовка таблицы, а также nrows — количество строк, которые нужно прочитать. В аргументе header всегда передается номер строки на единицу меньше, чем в Excel-файле, поскольку в Python индексация начинается с 0 (на рисунке это номер 5, тогда указываем 4):
pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
usecols='D:F',
header=4, # в excel это №5
nrows=3)
#
Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78
Читаем таблицы в OpenPyXL
Pandas прочитывает только содержимое таблицы, но игнорирует метаданные: цвет заливки ячеек, примечания, стили таблицы и т.д. В таком случае пригодится библиотека OpenPyXL. Загрузка файлов осуществляется через функцию load_workbook, а к листам обращаться можно через квадратные скобки:
from openpyxl import load_workbook
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
type(ws)
# openpyxl.worksheet.worksheet.Worksheet
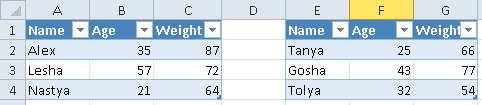
Допустим, имеется Excel-файл с несколькими таблицами на листе (см. рисунок выше). Если бы мы использовали Pandas, то он бы выдал следующий результат:
pd.read_excel(io='temp2.xlsx',
engine='openpyxl')
#
Name Age Weight Unnamed: 3 Name.1 Age.1 Weight.1
0 Alex 35 87 NaN Tanya 25 66
1 Lesha 57 72 NaN Gosha 43 77
2 Nastya 21 64 NaN Tolya 32 54
Можно, конечно, заняться обработкой и привести таблицы в нормальный вид, а можно воспользоваться OpenPyXL, который хранит таблицу и его диапазон в словаре. Чтобы посмотреть этот словарь, нужно вызвать ws.tables.items. Вот так выглядит Python-код:
ws.tables.items()
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
ws.tables.items()
#
[('Таблица1', 'A1:C4'), ('Таблица13', 'E1:G4')]
Обращаясь к каждому диапазону, можно проходить по каждой строке или столбцу, а внутри них – по каждой ячейке. Например, следующий код на Python таблицы объединяет строки в список, где первая строка уходит на заголовок, а затем преобразует их в DataFrame:
dfs = []
for table_name, value in ws.tables.items():
table = ws[value]
header, *body = [[cell.value for cell in row]
for row in table]
df = pd.DataFrame(body, columns=header)
dfs.append(df)
Если таблицы имеют одинаковые атрибуты, то их можно соединить в одну:
pd.concat(dfs)
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
0 Tanya 25 66
1 Gosha 43 77
2 Tolya 32 54
Сохраняем метаданные таблицы
Как указано в коде выше, у ячейки OpenPyXL есть атрибут value, который хранит ее значение. Помимо value, можно получить тип ячейки (data_type), цвет заливки (fill), примечание (comment) и др.
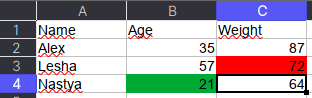
Например, требуется сохранить данные о цвете ячеек. Для этого мы каждую ячейку с числами перезапишем в виде <значение,RGB>, где RGB — значение цвета в формате RGB (red, green, blue). Python-код выглядит следующим образом:
# _TYPES = {int:'n', float:'n', str:'s', bool:'b'}
data = []
for row in ws.rows:
row_cells = []
for cell in row:
cell_value = cell.value
if cell.data_type == 'n':
cell_value = f"{cell_value},{cell.fill.fgColor.rgb}"
row_cells.append(cell_value)
data.append(row_cells)
Первым элементом списка является строка-заголовок, а все остальное уже значения таблицы:
pd.DataFrame(data[1:], columns=data[0])
#
Name Age Weight
0 Alex 35,00000000 87,00000000
1 Lesha 57,00000000 72,FFFF0000
2 Nastya 21,FF00A933 64,00000000
Теперь представим атрибуты в виде индексов с помощью метода stack, а после разобьём все записи на значение и цвет методом str.split:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
)
#
0 1
Name
Alex Age 35 00000000
Weight 87 00000000
Lesha Age 57 00000000
Weight 72 FFFF0000
Nastya Age 21 FF00A933
Weight 64 0000000
Осталось только переименовать 0 и 1 на Value и Color, а также добавить атрибут Variable, который обозначит Вес и Возраст. Полный код на Python выглядит следующим образом:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
.set_axis(['Value', 'Color'], axis=1)
.rename_axis(index=['Name', 'Variable'])
.reset_index()
)
#
Name Variable Value Color
0 Alex Age 35 00000000
1 Alex Weight 87 00000000
2 Lesha Age 57 00000000
3 Lesha Weight 72 FFFF0000
4 Nastya Age 21 FF00A933
5 Nastya Weight 64 00000000
Ещё больше подробностей о работе с таблицами в Pandas, а также их обработке на реальных примерах Data Science задач, вы узнаете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.

