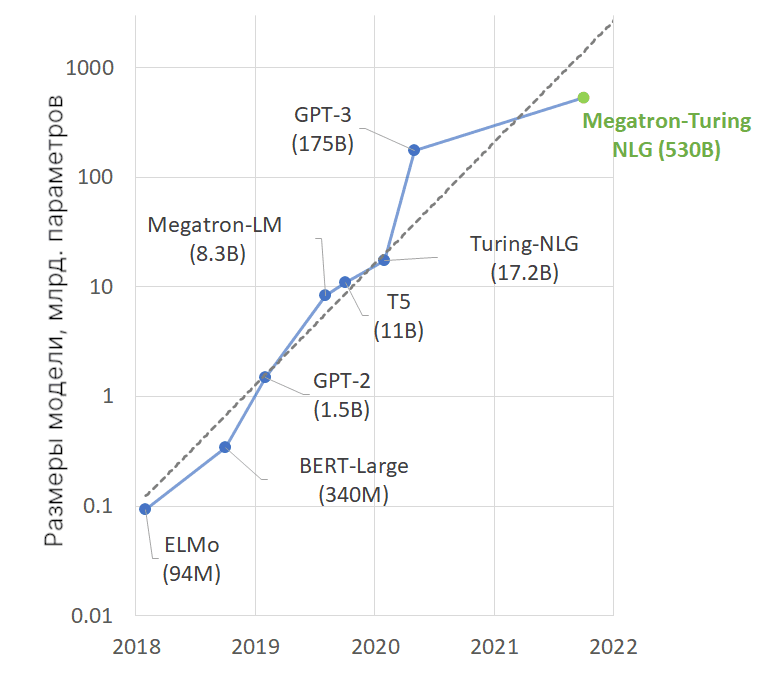
В октябре 2021 года Nvidia и Microsoft представили модель Megatron-Turing NLG 530B. Она объединяет модели DeepSpeed и Megatron и имеет 530 миллиардов параметров (109). Давайте же рассмотрим, что появилось на свет в в результате колаборации Nvidia и Microsoft, и чего они достигли в области обработки текстов на естественном языке (NLP).
MT-NLG имеет в виде своих предшественников Turing NLG 17B and Megatron-LM. Новая модель имеет в три раза больше параметров, чем существующая модель этого типа. Она также демонстрирует не имеющие себе равных показатели точности в таких задача как:
- предсказание следующих слов;
- понимание текстов;
- построение причинно-следственной связи;
- суммаризация;
- разрешение противоречий в словах;
Таким образом, трансформер MT-NLG со 105 слоями стал новым стандартом области передовых (state-of-the-art) моделей NLP.
NLP с Python
Код курса
PNLP
Ближайшая дата курса
по запросу
Продолжительность
40 ак.часов
Стоимость обучения
90 000 руб.
Масштабируемые модели NLP
С недавних лет NLP-трансформеры начали резко прогрессировать с увеличением размеров датасетов, улучшением алгоритмов и ПО, необходимых для их обучения.
Языковые модели с высоким числом параметров, на которые из-за этого тратятся больше времени для обучения, требуют более кропотливого понимания самого языка. В результате они обобщены настолько хорошо, что показывают высокую точность на различных задачах и датасетах. Например, их можно использовать в суммаризации, чат-ботах, переводах, семантическом поиске и автодополнения кода. Не удивительно, что количество параметров самых последних NLP-моделей экспоненциально растет (см. рис. ниже).
Но обучение таких моделей достаточно сложно, потому что:
- нет возможности впихнуть столько параметров этих моделей в память, даже в самые объемные GPU;
- чем больше параметров, тем дольше время ожидания, особенно если не уделено внимание оптимизации алгоритмов, ПО и железа.
Благодаря прорывам в области Machine Learning стало возможным обучение такой огромной модели, как MT-NLG. Например, разработчики из Microsoft и Nvidia повысили точность, проводя обучение на самых мощных ускорителях GPU и на ПО с самыми последними наработками в области распределенных вычислений. Был организован высококачественный тренировочный корпус с 100 миллиардов токенов, а также разработаны алгоритмы для оптимизации и надежности обучения.
Разберем, что использовалось для обучение такого огромного трансформера.
Масштабируемая инфраструктура
В разработке использовались такие инструменты, как
- NVIDIA A100 Tensor Core GPU,
- HDR InfiniBand networking (высокоскоростная сеть с расширенными динамическим диапазоном),
- суперкомпьютер Nvidia Selene,
- виртуальная машина Microsoft Azure NDv4.
С ними стало доступно обучение миллиардов параметров за приемлемое время. Однако для того, чтобы выжать на полную мощность весь этот стэк, требуется обеспечение паралеллизма по тысячам единиц GPU.
Существующие методы параллельных вычислений (например, разделяемые данные, пайплайны, разрезы тензоров (tensor-slicing)) имеют недостатки в виде чрезмерного использования памяти и неэффективных вычислений. По одному их применять для больших языковых моделей не получится, поэтому использовались все три метода.
Разработка ПО
Результатом колаборции между Nvidia Megatron-LM и Microsoft DeepSpeed стала высокоэффективная и параллельная система, которая объединяет параллелизм данных, пайплайнов и разрезов тензоров.
Комбинируя параллелизм tensor-slicing и пайплайнов, можно управлять ими тогда, когда они эффективны. Более конкретно, система использует разрез тензоров из Megatron-LM для масштабирования модели внутри узла и пайплайн из DeepSpeed для масштабирования модели по узлам.
Тренировочный датасет и настройка модели
Итак, модель состоит из 540 миллиардов параметров. Количество слоев = 105, скрытых измерений = 20480, “голов” внимания (attention heads) = 128.
Использовался параллелизм с 8-видовым тензор и 35-видовым пайплайном. Длина последовательности — 2048, размер батча — 1920. После первых 12 миллиардов тренировочных токенов постепенно увеличивался размер батча на 32 до тех пор, пока не дошли отметки 1920.
В основном обучение происходило на датасете Pile. Сначала были выбраны подмножество датасетов (включающие данные из Википедии, Github, Books3, Stack Exchange, etc) с самым лучшим качеством. Затем был скачаны и отфильтрованы два последних снимка Common Crawl (CC).
Шаги для генерации CC-датасета включали извлечение текста из HTML, оценка извлеченных документов через обученный классификатор, фильтрация документов на основании их оценок. Чтобы разнообразить тексты также были собраны датасеты RealNews и CC-Stories.
Удаление дублирующихся данных — важный шаг в построение тренировочного датасета. Для этого использовался процесс нечеткой дедубликации с использованием алгоритма min-hash LSH для расчета разреженного графа документа и связанных компонент.
Затем на основании приоритетов качества проходил выбор документа из дубликатов в каждом связном компоненте. Наконец, была использованы n-граммы для окончательной фильтрации.
Все это кончилось собрание 15 датасетов, которые суммарно содержат 339 миллиардов токенов. В процессе обучения было решено смешать 15 датасетов в гетерогенные батчи в соответствии с переменными весами. Таким образом, модель была обучена на 270 миллиардов токенов.
Результаты
В последнее время все чаще пользуются предобученными языковыми моделями даже без дообучения для решения собственных задач NLP.
Трансформер MT-NLG тестировался на задачах предсказания последующих слов, генерации ответов, разрешение кореференций, суммаризации и проч. Причем для тестирования использовался проект с открытым исходным кодом lm-evaluation-harness.
Улучшения появились в задачах сравнения и нахождения отношений между двумя предложениями. Данная задача не так хорошо решалась прошлыми моделями. Причем данная модель обучалась на меньшем количестве токенов для того, чтобы показать, что большие модели могут обучаться быстрее.
Также модель хорошо разбирается в математических нотациях, например, определяет арифметические операции по контексту даже несмотря на то, что они бывают слишком запутанными.
Еще MT-NLG справляется с ответами на вопросы лучше, чем предыдущие модели, причем даже без дообучения.
А вот об обучении языковых моделей с помощью языка Python на основе последних достижений в области NLP на специализированном курсе по машинному обучению «PNLP: NLP — обработка естественного языка с Python» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.