Продолжаем решать NLP-задачи на примере корпуса с русскоязычными twitter-постами, на основе которого мы получили датасет [вот здесь]. Сегодня мы расскажем, как построить и обучить свою word2vec-модель Machine Learning, используя Python-библиотеку Gensim.
Модель Word2vec на основе датасета русскоязычных twitter-постов
В предыдущей статье мы подготовили датасет: провели лемматизацию и удалили стоп слова из корпуса, который содержит twitter-посты на русском языке [1]. Вот так он сейчас выглядят:
>>> data 0 [школотый, поверь, самый, общество, профилиров... 1 [да, таки, немного, похожий, но, мальчик, равно] 2 [ну, идиотка, испугаться] 3 [кто, угол, сидеть, погибать, голод, ещё, порц... 4 [вот, значит, страшилка, но, блин, посмотреть,... ... 205174 [но, каждый, хотеть, исправлять] 205175 [скучать, вправлять, мозги, равно, скучать] 205176 [вот, школа, говно, это, идти] 205177 [тауриэль, грусть, обнять] 205178 [такси, везти, работа, раздумывать, приплатить...
Далее построим модель Word2vec, обученную на полученном датасете, с библиотекой Gensim [2].
Обучение модели Word2vec
Подготовив датасет, можем обучить модель. Для этого воспользуемся библиотекой Gensim и инициализируем модель Word2vec:
from gensim.models import Word2Vec
w2v_model = Word2Vec(
min_count=10,
window=2,
size=300,
negative=10,
alpha=0.03,
min_alpha=0.0007,
sample=6e-5,
sg=1)
Модель имеет множество аргументов:
min_count— игнорировать все слова с частотой встречаемости меньше, чем это значение.windоw— размер контекстного окна, о котором говорили тут, обозначает диапазон контекста.size— размер векторного представления слова (word embedding).negative— сколько неконтекстных слов учитывать в обучении, используя negative sampling, о нем также упоминалось здесь.alpha— начальный learning_rate, используемый в алгоритме обратного распространения ошибки (Backpropogation).min_alpha— минимальное значение learning_rate, на которое может опуститься в процессе обучения.sg— если 1, то используется реализация Skip-gram; если 0, то CBOW. О реализациях также говорили тут.
Далее, требуется получить словарь:
w2v_model.build_vocab(data)
А после уже можно обучить модель, используя метод train:
w2v_model.train(data, total_examples=w2v_model.corpus_count, epochs=30, report_delay=1)
Если в дальнейшем не требуется снова обучать модель, то для сохранения оперативной памяти можно написать следующее:
w2v_model.init_sims(replace=True)
Насколько похожи слова обученной модели Word2vec
После того, как модель была обучена, можем смотреть результаты. Каждое слово представляется вектором, следовательно, их можно сравнивать. В качестве инструмента сравнения в Gensim используется косинусный коэффициент (Cosine similarity) [3].
У модели Word2vec имеется в качестве атрибута объект wv, который и содержит векторное представление слов (word embeddings). У этого объекта есть методы для получения мер схожестей слов. Например, определим, какие слова находятся ближе всего к слову “любить”:
>>> w2v_model.wv.most_similar(positive=["любить"])
[('дорожить', 0.5577003359794617),
('скучать', 0.4815309941768646),
('обожать', 0.477267324924469),
('машенька', 0.4503161907196045),
('предновогодниеобнимашка', 0.4403109550476074),
('викуль', 0.43941542506217957),]
Число после запятой обозначает косинусный коэффициент, чем он больше, тем выше близость слов. Можно заметить, что слова “дорожить”, “скучать”, “обожать” наиболее близкие к слову “любить” Можно также рассмотреть другие слова:
>>> w2v_model.wv.most_similar(positive=["мужчина"])
[('женщина', 0.6242121458053589),
('девушка', 0.5410279035568237),
('любящий', 0.5005632638931274),
('парень', 0.4864271283149719),
('идеал', 0.45188209414482117),
('существо', 0.44532185792922974),
('недостаток', 0.4350862503051758),
('пёсик', 0.42453521490097046),
('послушный', 0.42428380250930786),
('эгоизм', 0.4202057421207428)]
...
>>> w2v_model.wv.most_similar(positive=["день", "завтра"])
[('сегодня', 0.6082668304443359),
('неделя', 0.5371285676956177),
('суббота', 0.48631012439727783),
('выходной', 0.4772387742996216),
('понедельник', 0.4697558283805847),
('денёчек', 0.4688040316104889),
('каникулы', 0.45828908681869507),
('подъесть', 0.4555707573890686),
('отсыпаться', 0.44570696353912354),
('аттестация', 0.4408838450908661)]
Векторы можно складывать и вычитать. Например, рассмотрим такой вариант: “папа” + “брат” — “мама”. Получили следующее:
>>> w2v_model.wv.most_similar(positive=["папа", "брат"], negative=["мама"])
[('младший', 0.3892076015472412),
('сестра', 0.31560415029525757),
('двоюродный', 0.3024488091468811),
('старший', 0.2937452793121338),]
Как видим, на этом корпусе результатом являются слова “младший”, “сестра”, “двоюродный”. Несмотря на то, что мы обучили модель на twitter-постах, получаем достаточно адекватные результаты.
Есть также возможность определить наиболее близкое слово из списка к данному слово. Для этого нужно воспользоваться методом:
>>> w2v_model.wv.most_similar_to_given("хороший", ["приятно", "город", "мальчик"])
'приятно'
Слово “приятно” из всего списка наиболее близок к слову “хороший”. Кроме того, так как для сравнения находится косинусный коэффициент, то его можно получить, написав:
>>> w2v_model.wv.similarity("плохой", "хороший")
0.5427995
>>> w2v_model.wv.similarity("плохой", "герой")
0.04865976
Само векторное представление слова можно получит либо напрямую, обратившись через квадратные скобки, либо через метод word_vec:
>>> w2v_model.wv.word_vec("страшилка")
array([-0.05101333, -0.03730767, 0.03676478, 0.18950877, 0.02496774,
0.00176699, -0.0966768 , 0.04010197, -0.00862965, -0.00530563,
...
dtype=float32)
>>> w2v_model.wv["страшилка"]
array([-0.05101333, -0.03730767, 0.03676478, 0.18950877, 0.02496774,
0.00176699, -0.0966768 , 0.04010197, -0.00862965, -0.00530563,
...
dtype=float32)
>>> w2v_model.wv.word_vec("страшилка").shape
(300,)
Векторное представление слов на плоскости
Так как слова в модели Word2vec — это векторы, то можно их выстроить на координатную плоскость. Поскольку каждый вектор модели имеет размерность 300, который был указан как аргумент size, то не предоставляется возможности построить 300-мерное пространство. Поэтому мы воспользуемся методом уменьшения размерности t-SNE, который есть в Python-библиотеке Scikit-learn [4], и снизим размерность векторов с 300 до 2. Согласно документации, если размерность больше 50, то стоит сначала воспользоваться другим методом уменьшения размерности — методом главных компонент PCA [5]. Для этого в аргументе достаточно указать init=”pca”.
В результате мы написали функцию, которая принимает входное слово и список слов и строит на плоскости входное слово, ближайшие к нему слова и переданный список слов:
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.manifold import TSNE
def tsne_scatterplot(model, word, list_names):
"""Plot in seaborn the results from the t-SNE dimensionality reduction
algorithm of the vectors of a query word,
its list of most similar words, and a list of words."""
vectors_words = [model.wv.word_vec(word)]
word_labels = [word]
color_list = ['red']
close_words = model.wv.most_similar(word)
for wrd_score in close_words:
wrd_vector = model.wv.word_vec(wrd_score[0])
vectors_words.append(wrd_vector)
word_labels.append(wrd_score[0])
color_list.append('blue')
# adds the vector for each of the words from list_names to the array
for wrd in list_names:
wrd_vector = model.wv.word_vec(wrd)
vectors_words.append(wrd_vector)
word_labels.append(wrd)
color_list.append('green')
# t-SNE reduction
Y = (TSNE(n_components=2, random_state=0, perplexity=15, init="pca")
.fit_transform(vectors_words))
# Sets everything up to plot
df = pd.DataFrame({"x": [x for x in Y[:, 0]],
"y": [y for y in Y[:, 1]],
"words": word_labels,
"color": color_list})
fig, _ = plt.subplots()
fig.set_size_inches(9, 9)
# Basic plot
p1 = sns.regplot(data=df,
x="x",
y="y",
fit_reg=False,
marker="o",
scatter_kws={"s": 40,
"facecolors": df["color"]}
)
# Adds annotations one by one with a loop
for line in range(0, df.shape[0]):
p1.text(df["x"][line],
df["y"][line],
" " + df["words"][line].title(),
horizontalalignment="left",
verticalalignment="bottom", size="medium",
color=df["color"][line],
weight="normal"
).set_size(15)
plt.xlim(Y[:, 0].min()-50, Y[:, 0].max()+50)
plt.ylim(Y[:, 1].min()-50, Y[:, 1].max()+50)
plt.title('t-SNE visualization for {}'.format(word.title()))
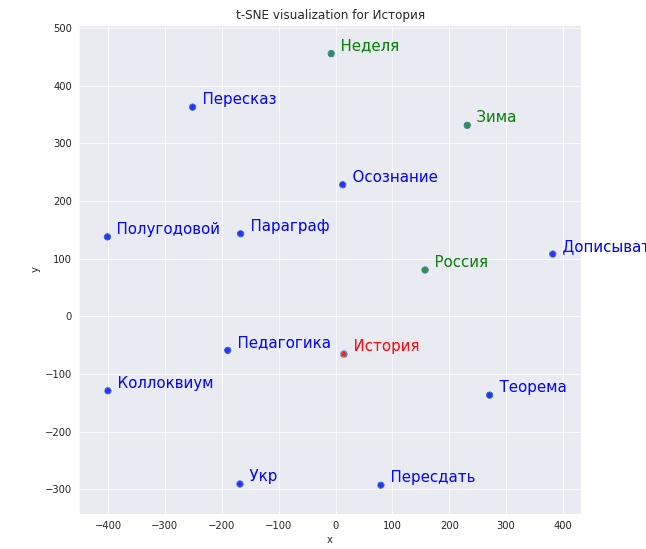
Далее рассмотрим, как далеко располагается слово “история” и слова «неделя», «россия», «зима»:
tsne_scatterplot(w2v_model, "история", ["неделя", "россия", "зима"])
Рисунок ниже показывает результат уменьшения размерности. Как видим, около истории находятся слова, связанные с учебой (“педагогика”, “теорема”), а вот “неделя”, которую мы передали как элемент списка, находится далеко от “истории”.
Мы переобучили модель, увеличив число эпох обучения (аргумент epoch в методе train) в два раза, и построили через ту же самую функцию систему координат:
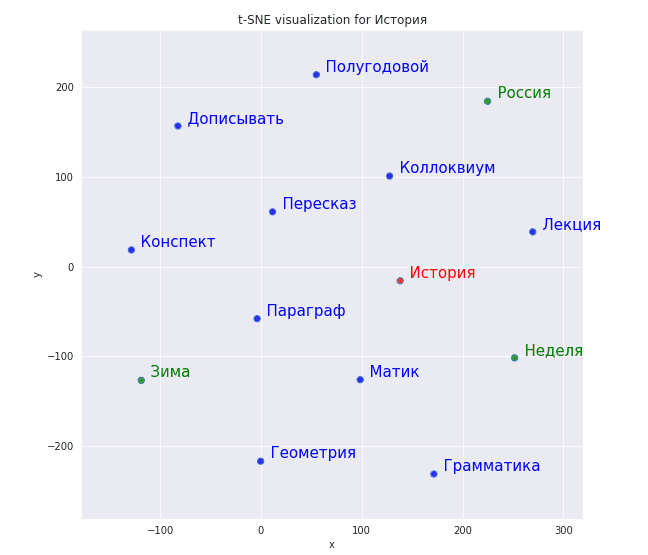
Результаты оправдали себя, с “историей” стало ассоциироваться больше слов, связанных с учебой и приблизилась к нему “неделя”. Machine Learning требует постоянного экспериментирования, поэтому важно всячески настраивать и перенастраивать свою модель.
Еще больше подробностей о NLP-моделях и особенностях их обучения на реальных примерах Data Science с помощью средств языка Python, вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
- Рубцова Ю. Автоматическое построение и анализ корпуса коротких текстов (постов микроблогов) для задачи разработки и тренировки тонового классификатора //Инженерия знаний и технологии семантического веба. – 2012. – Т. 1. – С. 109-116.
- https://radimrehurek.com/gensim/
- https://en.wikipedia.org/wiki/Cosine_similarity
- https://scikit-learn.org/stable/modules/generated/sklearn.manifold.TSNE.html
- https://ru.wikipedia.org/wiki/Метод_главных_компонент