Как уже было сказано в прошлый раз, существует несколько видов преобразования слов в числа. Одним из таких NLP-методов является Word Embeddings. В этой статье рассмотрим наиболее популярную разновидность Word Embeddings – нейросеть Word2Vec.
Архитектура Word2Vec состоит из 3 слоев
Нейронная сеть Word2Vec имеет две реализации: Skip-gram и CBOW (Сontinuous bag-of-words). Skip-gram состоит из следующих трех слоев:
- Входной слой, который принимает одно слово в формате one-hot, о котором говорилось тут. Суть one-hot encoding заключается в том, что слово кодируется бинарным вектором с одной единицей, которая представляет позицию слова в словаре:
{шла, саша, по, шоссе} # словарь [1, 0, 0, 0] # шла [0, 1, 0, 0] # саша [0, 0, 1, 0] # по [0, 0, 0, 1] # шоссеДлина one-hot вектора равняется размеру словаря.
- Слой Embedding, который представляет собой матрицу размером
 , где
, где  — размер словаря,
— размер словаря,  — гиперпараметр, который подбирается эмпирически. В оригинальной статье в качестве размера P используется значение 300 [1].
— гиперпараметр, который подбирается эмпирически. В оригинальной статье в качестве размера P используется значение 300 [1]. - Выходной слой с размером Nx1, где N — размер словаря. Это единственный слой, который имеет функцию активацию (softmax). Каждый из нейронов этого слоя выдает вероятность того, что входное слово принадлежит соответствующему контексту (другим словам).
 , где
, где  — гиперпараметр, который подбирается эмпирически. В оригинальной статье в качестве размера P используется значение 300 [1].
— гиперпараметр, который подбирается эмпирически. В оригинальной статье в качестве размера P используется значение 300 [1].Архитектура CBOW является зеркальным отражением Skip-gram, когда входной и выходной слой меняются местами: на вход подается контекст (множество слов), а модель предсказывает слово, подходящее этому контексту. Слой Embedding остается тем же.
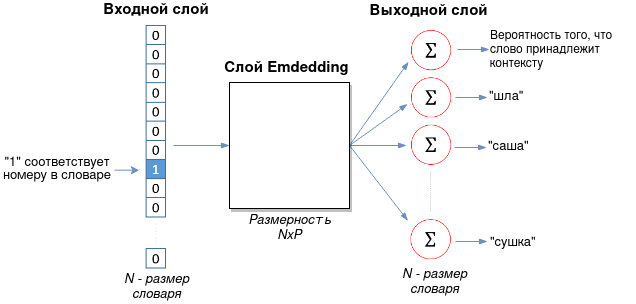
Представление входного и выходного векторов через контекстное окно
После создания словаря необходимо выбрать входное слово и контекст к нему. Под контекстом подразумевается ближайшие слова, образованные в зависимости от размера контекстного окна. Например, есть предложение “Шла Саша по шоссе и сосала сушку”. Выбираем слово “шоссе” в качестве входного слова и окно с размером 2. Тогда имеем по два контекста слева и справа:
- (шоссе, и), (шоссе, сосала).
- (по, шоссе), (Саша, шоссе).
Число контекстных слов зависит от количества предложений и размера окна. Алгоритм word2vec ищет все предложения с входным словом и контекстом около него. Исходя из нашего предложения, можно составить входной и выходной векторы для одного слова:
{шла, саша, по, шоссе, и, сосала, сушку}
X_1 = [0, 0, 0, 1, 0, 0, 0] # входное слово “шоссе”
Y_1 = [0, 1, 1, 1, 1, 1, 0] # контекст (слова “шла” и “сушку” в него не входят)
Именно Y_1 является тем вектором, с которым сравниваются результаты выходного слоя.
Извлекаем из слоя Embedding только одну строку
Входной вектор (one-hot) умножается на матрицу Embedding, как это показано на рисунке ниже.
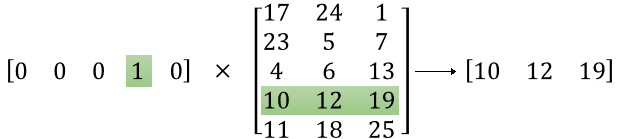
В итоге, из всей большой матрицы NxP выбирается только одна строка-вектор, которая и является векторным представлением слова (word embedding). Эта строка-вектор посылается на выходной слой, каждое соединение с нейроном которого имеет свои веса.
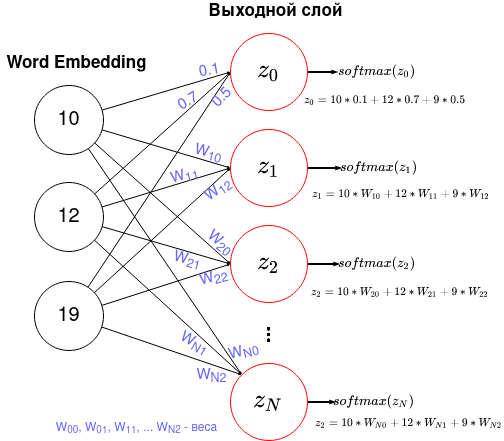
Выходной слой с функцией активацией softmax
Выходной слой содержит N нейронов с функцией активацией softmax, где N — размер словаря. Каждый нейрон соединен со слоем Emdedding. Рисунок ниже показывает эти соединения, где для нулевого нейрона показаны числовые значения весов.
Функция softmax вычисляется по следующей формуле:
![\[ softmax(z_i)=\frac{\exp(z_i)}{\sum_{k=0}^{N} \exp(z_k)} \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-cfa6d7d4d8d8519eed27cdc539d9adb4_l3.png "Rendered by QuickLaTeX.com")
Значение функции softmax – это вероятность того, что ответ правильный. Благодаря знаменателю, значения функции активации всех нейронов дадут в сумме 1.
Функция потерь считается вычисляется как
![\[ L=-sum(Y*\log{Y_{pred}}) \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-05a58540ccd87043367ed3d8b9c17335_l3.png "Rendered by QuickLaTeX.com")
Минус стоит потому, что логарифм от чисел меньше 1 — отрицательный. На языке Python это может быть выражено следующим образом:
import np L = np.sum(Y*np.log(Y_pred))
Эту функцию и нужно минимизировать, изменяя значения весов и матрицу Emdedding через алгоритм обратного распространения ошибки.
Дополнительные улучшения: Phrase Learning, Subsampling, Negative Sampling
Также авторы Word2Vec добавили некоторые улучшения в модель, а именно Phrase Learning, Subsampling и Negative Sampling, вместо которого можно использовать Hierarchical softmax. Рассмотрим эти инструменты подробнее.
Phrase Learning, означает, что некоторые слова стоит рассматривать вместе, например, “New_York”. Слово “New” в некоторых случаях может обозначать “новый”, но если “New” и “York” стоят вместе, то, скорее всего, имеется в виду “Нью-Йорк”. Также это поможет различать людей: “Петр_Сидоров” от “Петр_Козлов”.
Subsampling подразумевает избавление от слишком повторяющихся слов.a Предлоги, союзы могут быть в каждом контексте, но не раскрывать его смысл. Для каждого слова вычисляется вероятность того, что оно должно учитываться в обучении. Такая вероятность вычисляется следующим образом:
![\[ P(w_i)=\frac{0.001}{f(w_i)}\sqrt{\frac{f(w_i)}{0.001}} \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-56926a71dd65a6efce632e48f09ba094_l3.png "Rendered by QuickLaTeX.com")
где —  слово, а
слово, а  — частота встречаемости этого слова в корпусе. Таким образом, чем больше , тем выше вероятность того, что слово не имеет информативной ценности.
— частота встречаемости этого слова в корпусе. Таким образом, чем больше , тем выше вероятность того, что слово не имеет информативной ценности.
Negative Sampling необходим для уменьшения вычислительных затрат на обучение. Выходной слой имеет размерность N, равный размеру словаря. Если словарь содержит миллион слов, то и обновлять веса для каждого нейрона слишком затратно. Поэтому обновление весов можно осуществлять только для контекстных слов и 5-6 слов, которые не совпадают с контекстом (для большого датасета можно ограничиться 2-3). Кроме того, Negative sampling можно заменить на Hierarchical softmax, который разворачивает сеть в бинарное дерево, обновляя  весов вместо
весов вместо  весов.
весов.
В следующей статье расскажем о том, как обучить модель Word2Vec с примерами кода на Python. Еще больше подробностей о NLP-задачах в реальных проектах Data Science вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
[…] о Word2Vec можно узнать тут. Векторное […]