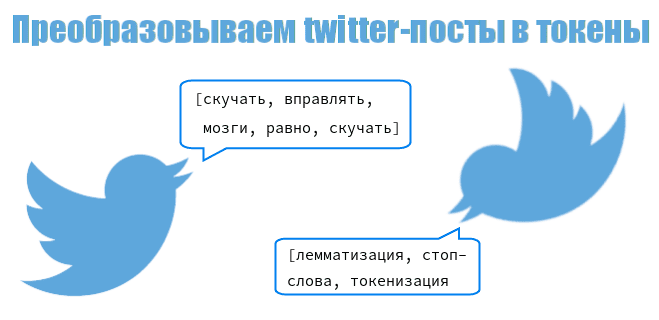
В прошлый раз мы разобрали, как обработать текстовые данные с помощью разных Python-библиотек. Сегодня мы расскажем, как с помощью Python подготовить настоящий датасет с разнообразными twitter-постами на русском языке перед созданием модели Machine Learning.
Модель Word2vec на основе датасета русскоязычных twitter-постов
В качестве примера построим модель Word2vec, обученную на русскоязычном корпусе коротких текстов RuTweetCorp, который собран Ю.Рубцовой [1]. Корпус разбит на два класса: твиты с положительной и с отрицательной окрасками. Для обработки нам понадобится всего две библиотеки:
- Pymorphy2 для лемматизации [2].
- NLTK, который имеет список стоп-слов [3].
Прежде всего требуется скачать корпус, как отрицательных, так и положительных твитов, в формате CSV (Comma separated-values) вот здесь. После установки обеих Python-библиотек необходимо получить стоп-слова от NLTK. Это можно сделать, написав в среде разработке, например, Jupyter Notebook, следующее:
import nltk
nltk.download('stopwords')
Соединяем файлы с негативными и позитивными twitter-постами в один большой датасет
Как уже говорилось, корпус разбит на два класса под названием negative.csv и positive.csv. Прочитаем файлы через Python-библиотеку Pandas. Заметим, что данные разделены не запятой, а двоеточием, поэтому ставим аргумент sep=";":
import pandas as pd
df_pos = pd.read_csv("/content/positive.csv", sep=";", header=None)
df_neg = pd.read_csv("/content/negative.csv", sep=";", header=None)
Оба файла имеет множество столбцов, таких как имя автора поста, дата публикации и т.д., но нас интересует только сами twitter-посты. Индекс столбца с постами стоит под номером 3; посмотрим, какие тексты содержаться в корпусе с позитивными постами:
>>> df1.iloc[:, 3] 0 @first_timee хоть я и школота, но поверь, у на... 1 Да, все-таки он немного похож на него. Но мой ... 2 RT @KatiaCheh: Ну ты идиотка) я испугалась за ... 3 RT @digger2912: "Кто то в углу сидит и погибае... 4 @irina_dyshkant Вот что значит страшилка :D\nН... ... 114906 Спала в родительском доме, на своей кровати...... 114907 RT @jebesilofyt: Эх... Мы немного решили сокра... 114908 Что происходит со мной, когда в эфире #proacti... 114909 "Любимая,я подарю тебе эту звезду..." Имя како... 114910 @Ma_che_rie посмотри #непытайтесьпокинутьомск ...
И тот, и другой файл содержат чуть более 100000 записей. Поскольку для нас не имеет значения позитивные или негативные посты (мы строим общую картину), соединим оба файла в один, отбросив пустые записи и дубликаты:
df = df_pos.iloc[:, 3].append(df_neg.iloc[:, 3]) df = df.dropna().drop_duplicates()
Проводим токенизацю, лемматизацию и удаляем стоп-слова
Как уже было рассказано тут, прежде в работе с NLP-задачами требуется нормализовать данные. В данном случае, мы проведем лемматизацию и удалим стоп-слова, воспользовавшись Python-библиотеками pymorphy2 и NLTK соответственно.
Мы уже создали DataFramе из двух файлов, поэтому просто используем метод apply, который применяет пользовательскую функцию к каждой записи DataFrame. Эту функцию мы и создадим, в которой:
- избавимся от букв латинского алфавита, чисел, знаков препинания и всех символов, например, символ @ встречается почти везде;
- разобьем пост на токены;
- проведем лемматизацияю, получив нормальную (начальную) форму слова;
- удалим стоп-слова.
Вот эта функция lemmatize сделает все вышеперечисленное:
import re
from pymorphy2 import MorphAnalyzer
from nltk.corpus import stopwords
patterns = "[A-Za-z0-9!#$%&'()*+,./:;<=>?@[\]^_`{|}~—\"\-]+"
stopwords_ru = stopwords.words("russian")
morph = MorphAnalyzer()
def lemmatize(doc):
doc = re.sub(patterns, ' ', doc)
tokens = []
for token in doc.split():
if token and token not in stopwords_ru:
token = token.strip()
token = morph.normal_forms(token)[0]
tokens.append(token)
if len(tokens) > 2:
return tokens
return None
Стоит обратить внимание, что переменные patterns, stopwords_ru и morph инициализированы вне функции lemmatize, так как создавать их для каждой записи не имеет смысла — они не изменяются. Переменная patterns нужна чтобы избавиться от всех некириллических символов и используется в функции re.sub. Переменная morph – это морфологический анализатор, который используется для нахождения нормальной формы слова. Функция lemmatize возвращает список слов (токенов), причем только тех постов, который содержат более 2 слов.
Остается только применить функцию к объекту DataFrame:
data = df.apply(lemmatize)
Обработка в Google Colab занимает около 5 минут, то есть примерно 40000 записей за 1 минуту. Можем посмотреть на результат:
>>> data = data.dropna() >>> data 0 [школотый, поверь, самый, общество, профилиров... 1 [да, таки, немного, похожий, но, мальчик, равно] 2 [ну, идиотка, испугаться] 3 [кто, угол, сидеть, погибать, голод, ещё, порц... 4 [вот, значит, страшилка, но, блин, посмотреть,... ... 205174 [но, каждый, хотеть, исправлять] 205175 [скучать, вправлять, мозги, равно, скучать] 205176 [вот, школа, говно, это, идти] 205177 [тауриэль, грусть, обнять] 205178 [такси, везти, работа, раздумывать, приплатить...
Самые распространенные слова в датасете
Есть возможность также посмотреть на самые распространенные слова во все обработанном датасете. Для этого воспользуемся особым словарем — defaultdict. В случае если ключ отсутствует в этом словаре, то ему присваивается значение по умолчанию, соответствующее переданному типу данных: значение по умолчанию для int — 0, для float — 0.0, для str — “” и т.д. От нас требуется всего лишь пройтись по токенам датасета:
from collections import defaultdict
word_freq = defaultdict(int)
for tokens in data.iloc[:]:
for token in tokens:
word_freq[token] += 1
Можем взглянуть сколько уникальных слов и 10 самых повторяющихся слов:
>>> len(word_freq) 98237 >>> sorted(word_freq, key=word_freq.get, reverse=True)[:10] ['это', 'я', 'весь', 'хотеть', 'день', 'ты', 'такой', 'а', 'сегодня', 'быть']
Как видим, самые распространенные слова оказались не самыми информативными.
В следующей статье расскажем, как на полученном датасете обучить модель Word2Vec с помощью Python-библиотеки Gensim. А как подготовить данные для Machine Learning в реальных примерах Data Science, вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
- Рубцова Ю. Автоматическое построение и анализ корпуса коротких текстов (постов микроблогов) для задачи разработки и тренировки тонового классификатора //Инженерия знаний и технологии семантического веба. – 2012. – Т. 1. – С. 109-116.
- https://pymorphyreadthedocs.io/en/latest/index.html
- https://www.nltk.org/