В прошлый раз мы говорили о предварительной обработке и векторизации текстов в NLP. Сегодня рассмотрим, как обучить алгоритмы машинного обучения (Machine Learning) на обработанных и векторизованных данных. Читайте в нашей статье о решении задач классификации на примере отзывов к фильмам с помощью нейронных сетей и векторных представлений слов (word embedding) в TensorFlow на Python.
IMDB: датасет с отзывами к фильмам
Для примера будем использовать датасет IMDB, который содержит 50000 отзывов и словарь с 88584 словами. Он поставляется в составе TensorFlow. Чтобы загрузить данные IMDB, требуется указать количество наиболее встречающихся слов. Выберем 10000 таких слов:
from tensorflow.keras.datasets import imdb max_words = 10000 (x_train, x_label), (y_test, y_label) = imdb.load_data(num_words=max_words)
x_trainиy_trainхранят массивы отзывов, каждый их которых составляет список индексов слов:>>> x_train array([list([1, 14, 22, 16, 43, 530, ...]), list([1, 194, 1153, 194, 8255, ...]), list([1, 14, 47, 8, 30, 31, 7, ...]), ... ], dtype=object)Поскольку мы выбрали значение
max_words, равное 10000, то ни один из отзывов не содержит слово с индексом 10000 и более.x_testиy_testхранят категории каждого отзыва: негативный — 0 или позитивный — 1:>>> x_label array([1, 0, 0, 1, 0, ...)
Для преобразования слов из индексов надо написать следующее:
word_index = imdb.get_word_index() reverse_word_index = dict([(value, key) for key, value in word_index.items()])
После этого можно посмотреть, что стоит под каждым индексом (кроме 0, так он зарезервирован как начало словаря):
>>> reverse_word_index[1], reverse_word_index[10]
('the', 'i')
Преобразуем отзывы разной длины в двумерный массив фиксированного размера
Каждый отзыв в датасете имеет разное количество слов, поэтому все списки с индексами не одинаковой длины. Однако, алгоритмы Machine Learning требуют на входе массивов одинакового размера. В библиотеке TensorFlow есть функция pad_sequence [1], которая преобразует список в двумерный тензор (матрицу). Длина преобразованного тензора определяется параметром maxlen, поэтому большие отзывы будут усечены, а маленькие, у которых количество слов меньше maxlen, будут заполнены 0.
from tensorflow.keras.preprocessing.sequence import pad_sequences maxlen = 50 x_train = pad_sequences(x_train, maxlen=maxlen) y_test = pad_sequences(y_test, maxlen=maxlen)
Теперь форма тренировочного и тестового наборов имеет вид:
>>> x_train.shape, y_test.shape (25000, 50), (25000, 50)
А сам отзыв — это одномерный тензор (вектор), длина которого равна maxlen:
>>> y_test[0]
array([ 394, 354, 4, 123, 9, 1035, 1035, 1035, 10, 10, 13,
92, 124, 89, 488, 7944, 100, 28, 1668, 14, 31, 23,
27, 7479, 29, 220, 468, 8, 124, 14, 286, 170, 8,
157, 46, 5, 27, 239, 16, 179, 2, 38, 32, 25,
7944, 451, 202, 14, 6, 717], dtype=int32)
Обучаем модель со слоями Emedding и Dense в TensorFlow
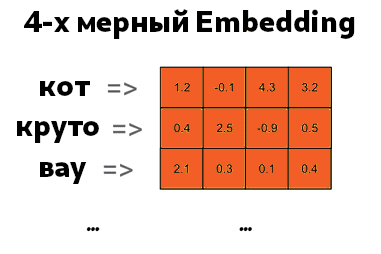
После того как мы подготовили данные, можем обучить модель машинного обучения. Для этого будет использовать слой Embedding – векторное представление слова, о котором также шла речь тут. В его основе лежит векторизация каждого слова, в нашем случае их 10000 (max_words). Слой Embedding инициализирует веса случайным образом, которые постепенно корректируются с помощью алгоритма обратного распространения ошибки. Вот так может выглядеть 4-мерный Embedding для слов:
Слой Embedding принимает в качестве аргументов следующие параметры:
input_dim— размер словаря. В нашем случае мы ограничились 10000.output_dim— размерность выходной матрицы Embedding. Например, на изображение выше — это 4. Выбирается этот параметр эмпирическим путем: в зависимости от точности модели его можно уменьшать или увеличивать.input_length— размерность входного слоя. В нашем случае это 50, так как мы преобразовали отзывы в вектор с 50-ю элементами (maxlen).
Архитектура модели простая:
- слой Flatten, который выпрямляет слой Embdedding;
- всего один выходной нейрон с функцией активацией
sigmoid, который выводит вероятность принадлежности к классу 1 (позитивный отзыв) или 0 (негативный отзыв).
Это реализуется следующим кодом на Python:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, Flatten
model = Sequential()
model.add(Embedding(
input_dim=max_words, output_dim=4, input_length=maxlen))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
Чтобы посмотреть гиперпараметры архитектуры, можно вызвать метод summary:
>>> model.summary() Model: "sequential_3" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_2 (Embedding) (None, 50, 4) 40000 _________________________________________________________________ flatten_2 (Flatten) (None, 200) 0 _________________________________________________________________ dense_2 (Dense) (None, 1) 201 ================================================================= Total params: 40,201 Trainable params: 40,201 Non-trainable params: 0
Теперь можем обучить модель. Выберем adam в качестве оптимизатора, функцию потерь binary_crossentropy и будем обучать на 15 эпохах:
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(
x_train,
y_train,
epochs=15,
batch_size=128,
validation_split=0.1)
Модель показала точность 96 % на тренировочном наборе данных и 80 % на валидационном. Это говорит о переобучении. С этим можно бороться, построив более сложную архитектуру или выбрав другую размерность матрицы Embedding.
Кроме того, можно получить вектор для какого-либо слова. У атрибута модели layers есть метод get_weights, который возвращает список матриц Embedding. Все что требуется, это узнать индекс слова. Для этого воспользуемся словарем с индексами word_index. Посмотрим на вектор для слова bad:
>>> word_index = imdb.get_word_index()
...
>>> word = 'bad'
>>> word_number = word_index[word]
>>> word_vector = embedding_matrix[word_number]
...
>>> word, word_number, word_vector
('bad',
75,
array([ 0.02339355, 0.03405639, -0.01444883, 0.01744975], dtype=float32))
Как видим, слово bad имеет индекс 75, а его подкорректированный в результате обучения вектор состоит из 4-х элементов.
Также смотрите в видеобзоре, как использовать предобученную модель векторного представления слов для решения задачи регрессии [2]. А освоить Python на реальных проектах Data Science для решения NLP-задач машинного обучения вы можете на наших курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.