Графовые нейронные сети (GNN) все больше интересуют крупные компании. В этот раз порадовал LinkedIn, разработчики которого разработали сеть PASS (Performance-Adaptive Sampling Strategy). В этой статье поговорим немного о ней и об общей ситуации в GNN.
PASS работает с атрибутами соседних вершин
Графы — это универсальный способ представления связи между сущностями. В машинном обучении (Machine Learning) для таких связей используются графовые нейронные сети (GNN). Однако применительно к социальным сетям GNN пока не показывают высоких результатов. Когда их используют для определения связей между друзьями, знакомыми или коллегами, то они могут не посчитать некоторые нюансы и сложные отношения. Это усложняет задачу LinkedIn, Twitter, Instagram и проч. выдавать точные рекомендации.
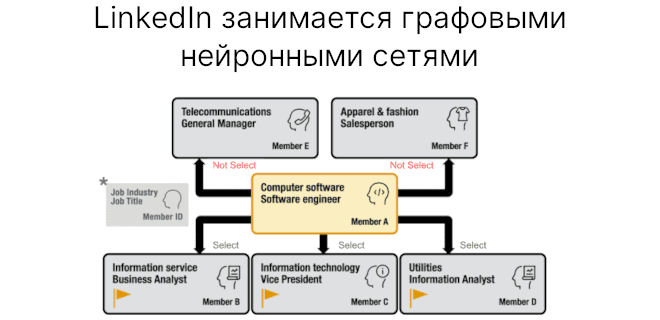
Чтобы это устранить в LinkedIn была разработана модель Performance-Adaptive Sampling Strategy (PASS)). Она подбирает соседние вершины в графе, которые наиболее релевантны.
Сразу после применения новой графовой модели в своих движках, разработчики опубликовали исходные коды. Ссылка на модель тут.
При использовании PASS выбираются соответствующие соседи на основании их атрибутов. Также он помогает обнаружить ботов или фейковые аккаунты среди соседей путем изучения их связй.
PASS достигла высокой точности, несмотря на то, что меньшее количество соседей, чем другие модели. Она обогнала другие модели на 10.4%. Даже с добавлением зашумленных данных, она показала точность в 3 раза больше.
Графовые нейронные сети в социальных сетях
Традиционные графовые нейронные сети плохо масштабируются до социальных сетей из-за того что работают со слишком большим количеством связей, не все из которых являются актуальными данной задаче. Например, среди связей одного человека могут быть работающие в разных сферах друзья, что приводит к уменьшению точности рекомендательной системы. В то же время какая-нибудь публичная личность может иметь связи, выходящими за пределы числа Данбара, т.е. более 200 человек, с которыми существует тесная связь. Поэтому такие большие связи невозможно посчитать.
Следовательно, главная проблема построения моделей в социальных связей — это большое и изменяющееся количество данных, необходимых для рассмотрения. Некоторые существующие методы попытались преодолеть эту проблему путем определения фиксированного числа соседей. Но такие выборки — нерепрезентативны, поскольку не рассматривают, как действительно соотносятся связи друг с другом.
IBM и Yale работают над своей моделью GNN
Другие организации также занимаются улучшением графовых нейронных сетей. Так, например, Йельский университет совместно с IBM предложили свой метод под названием Kernel Graph Neural Networks (KerGNNs), который внедряет графовые ядра в способ передачи сообщений в GNN. Это процесс, при котором вектор сообщений обменивается между вершинами в графе и обновляется. Применение модели KerGNNs привела к повышению интерпретируемости по сравнению с другими графовыми моделями.
Компания Google еще в ноябре прошлого года опубликовала возможность построения GNN в составе TensorFlow. Поэтому можно ожидать, что крупные игроки хотят освоить сферу графовых сетей, ведь здесь еще не достигнуто высоких результатов.
Код курса
GRAS
Ближайшая дата курса
по запросу
Продолжительность
ак.часов
Стоимость обучения
0 руб.
А об основах графовых алгоритмах на реальных примерах из Data Science вы узнаете на специализированном курсе «Графовые алгоритмы в Apache Spark» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.