
Pandas хоть и является популярной библиотекой Python, но плохо работает при параллельной обработки.Поэтому вам может пригодиться новая библиотека Modin, которая обещает быть быстрее, при этом имеет тот же API, что и Pandas.
Pandas не работает на больших данных
Библиотека Pandas является одной из самых популярных библиотек обработки и анализа данных на Python. Популярность библиотеки объясняется возможностью гибкой манипуляции данными. В отличие от традиционных СУБД Pandas более удобен в использовании.
Однако гибкость, выразительность и удобство имеет свою цену. Самый главный минус Pandas — библиотека плохо работает с большими данными (Big Data). Это объясняется двумя причинами:
- Операции происходят в оперативной памяти, а её не всегда много;
- Операции выполняются на одном треде.
Эти недостатки пытается преодолеть библиотека Modin. Она всё больше набирает популярность. Интересно заметить, что разработчики сделали точно такой же API как у Pandas, поэтому единственное, что требуется для миграции так это изменить импорт библиотек с pandas на modin.pandas.
Что не так с параллельной обработкой в Pandas?
Оптимизация 600+ функций — занятие очень затруднительное, а именно столько предоставляет Pandas API. К тому же эти функции могут быть представлены в виде конвейера (начиная от чтения датасета, заканчивая преобразованиями) по-разному, что ведёт к экспоненциальному росту необходимых оптимизаций.
При этом если посмотреть на реляционные базы данных, то в них вопросом по оптимизации запросов занимались более 40 лет. Причина, по которой SQL-запросы легко распараллелить, заключается в том, что там меньше 10 операторов: фильтры, проекция, группировка, соединение и др. Четыре десятка понадобилось, чтобы добиться оптимизации и поддержки параллелизации каждого оператора.
Если сообщество 40 лет занималась улучшением 10 операторов, то сколько времени займет улучшение 600+ функций в Pandas? Также существуют различие между таблицами реляционных баз данных и фреймами данных, что ещё усложняет этот процесс. У нас нет 40 лет, поэтому должен быть придуман другой способ.
Как устроен Modin
Как утверждают разработчики Modin, Pandas API может быть представлен менее 20 операторами. Эти операторы могут быть применены для любой оси: строки, столбца или конкретной записи. Например, min принимает в качестве параметра ось, по которой нужно посчитать минимальное значение вдоль строк или столбцов. В реляционных операторах такое можно применить только для одной оси (например, фильтры применяются только для строк).
К основным операторам относятся:
- низкоуровневые (
map,explode,reducе); - реляционные (
groupby,join,rename,sort,concat,filter); - для линейной алгебры (
transpose); - порядковые (
window,mask).
Разработчики Modin разработали набор правил декомпозиции, Они позволяют переписать основные операторы в виде мелких операций, которые применяются в параллельном режиме для партиций (вертикальных, горизонтальных, блочных). Вид партиции определяется операцией. Например, операция min, которая применяется построчно/поколочно может быть разложена и применена к различным горизонтальным/вертикальным партициям с последующим пересобиранием разбитого на партиции фрейма данных обратно в горизонтальном/вертикальном порядке.
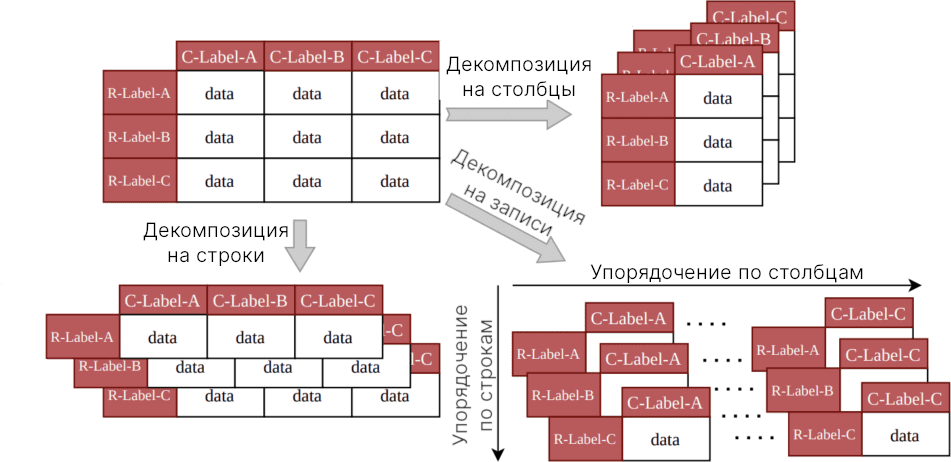
Оператор декомпозиции достаточно прост, но фрейм данных имеет уникальные свойства, которые делает параллелизм сложным, например, использование логического порядка и смешанных типов в столбце. Типы столбцов фрейма данных, подверженного декомпозиции, могут меняться самым непредсказуемым образом, требуя дорогой координации. Наиболее сложный аспект фреймов данных — это построчный параллелизм с последующим поколоночным параллелизмом, поэтому традиционные способы оптимизации не работают. Вы можете более подробно ознакомиться с этой алгеброй в VLDB2021, а также о правилах декомпозиции в VLDB2022.
Сравнение производительности Pandas и Modin
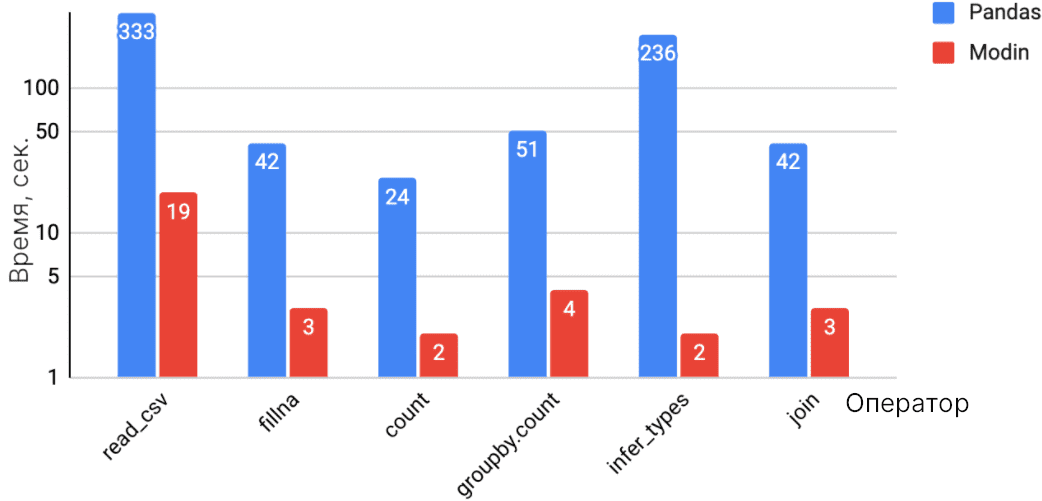
На основе декомпозиции Modin может эффективно использовать ядра машины или кластера для параллелизации операций Pandas. Это позволяет повысить производительность. Кроме того, Modin избегает лишние копирования в памяти и использует принципы сжатия. Также библиотека позволяет применять механизм данные за пределами памяти (Out-of-memory data), когда память на исходе.
Подготовка данных для Data Mining на Python
Код курса
DPREP
Ближайшая дата курса
по запросу
Продолжительность
32 ак.часов
Стоимость обучения
72 000 руб.
Больше подробностей о Modin вы узнаете на специализированном курсе «DPREP: Подготовка данных для Data Mining на Python» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

