В помощь Data Scientist’ам: Jigsaw генерирует и исправляет код
Microsoft давно работает в направлении Deep Learning, они уже давно нацелены на возможность ИИ заменить программиста или хотя бы предоставить ему помощника. Именно для второй задачи была разработана языковая модель Jigsaw — инструмент для генерации и редактуры кода Pandas API.
Для чего нужен Jigsaw
NLP с Python
Код курса
PNLP
Ближайшая дата курса
по запросу
Продолжительность
40 ак.часов
Стоимость обучения
90 000 руб.
Jigsaw предназначен для синтеза кода Pandas API, библиотеки Python. Поэтому новая модель пригодится не сколько программистам, сколько Data Scientist’ам.
Языковые модели, как Codex, позволяют разработчикам на основе описания задачи на английском языке генерировать код на каком-нибудь языке программирования, например, Python или JavaScript. Но этот код может быть неправильным или содержать ошибки, поэтому разработчикам нужно его проверять.
Поэтому Jigsaw необходим для проверки такого кода и будет полезен всем тем, кто использует языковые модели для генерации кода. Стоит отметить, что он корректирует то, что написано с помощью библиотеки Pandas. Вместо самостоятельного запоминания функций Pandas, можно предоставить описание на английском языке, что нужно сделать с исходным датафреймом. Вместо чтения документации или поиска ответа на StackOveflow, разработчик просто пишет свое намерение (например, модифицировать столбец с строкой) и отдает это на вход Jigsaw.
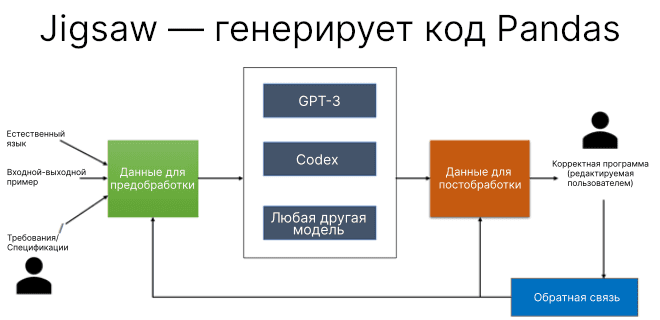
Как Jigsaw работает
Jigsaw принимает описание на английском языке, обрабатывает его с подходящим контекстом для построения входных данных, которые могут быть переданы в языковые модели. Модель рассматривается как черный ящик, она может быть любой; Jigsaw оценивалась и на GPT-3, и на Codex. Как только модель гененрирует выходной код, Jigsaw проверяет удовлетворяет ли переданному описанию.
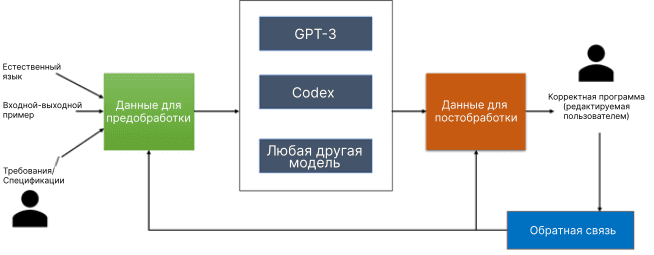
Если же не удовлетворяет (а тесты показывают, что так происходит в 30% случаев), то начинается повторная обработка. На этой стадии Jigsaw применяет три вида трансформации для редактуры кода. Эти трансформации необходимы из-за тех ошибок, которые сотрудники Microsoft обнаружили в GPT-3 и Codex. Причем обе модели ошибаются схожим образом, поэтому постобработка от Jigsaw полезна для обеих.
Преобразования переменных
Было обнаружено, что Codex может выдавать неправильные имена переменных. Например, многие пользуются такими именами как df1, df2 и т.д. Codex использует именно эти имена. Если разработчик назовет свои датафреймы, скажем, g1, g2, то Codex вероятно выдаст обыденные df1, df2, что является ошибкой. Также Codex и вовсе путает переменные. Например, df2.merge(df1) вместо df1.merge(df2).
Чтобы вычислить эти ошибки, Jigsaw заменяет имена в генерируемом код от Codex на всевозможные имена в пространстве имен до тех пор, пока не найдет ту программу, которая удовлетворяет входному описанию.
Преобразования аргументов
Иногда Codex генерирует такой код, в котором неправильные аргументы функции или их вовсе нет. Например,
а) Запрос — выбросить все строки, которые есть в столбце inputB.
dfout = dfin.drop_duplicates(subset=['inputB']) # Модель dfout = dfin.drop_duplicates(subset=['inputB'], keep=False) # Правильно
б) Запрос — заменить все Canada на CAN в столбце в со странами.
df = df.replace({'Canada':'CAN'}) # Модель
df = df.replace({'country': {'Canada':'CAN'}) # Правильно
Чтобы исправить эти ошибки, Jigsaw систематически перечисляет все возможные аргументы функции и их комбинации до тех пор, ока не найдется программа, которая удовлетворяет описанию.
Оценка производительности
Codex выдавал точность около 30%, что и ожидалось, ориентируясь на публикацию OpenAI. Jigsaw улучшал это число до 60%, а вместе с обратной связью от пользователя — до 80%.
Процент пока неубедительный, но надеемся, что Microsoft найдут, что улучшить.
NLP с Python
Код курса
PNLP
Ближайшая дата курса
по запросу
Продолжительность
40 ак.часов
Стоимость обучения
90 000 руб.
О том, как строить свои NLP-модели вы узнаете на специализированном курсе «CURS» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

