В прошлый раз мы разбирали на практическом примере, как работать с SQLite в Python. Помимо прочего, встроенная СУБД также просто интегрируется с библиотекой Pandas, которая применяется для работы с данными в Data Science. Сегодня мы расскажем о том, как добавить данные из DataFrame в базу данных и, наоборот, как из записей БД получить DataFrame.
Читаем таблицы User и Language
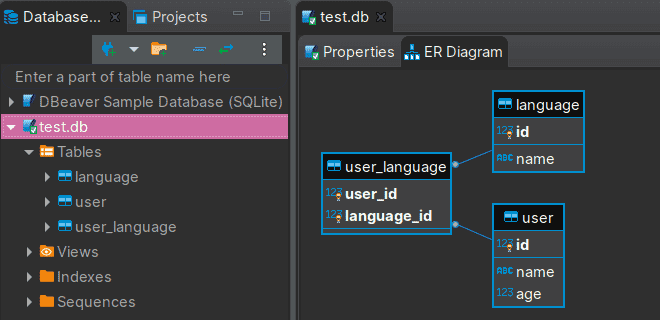
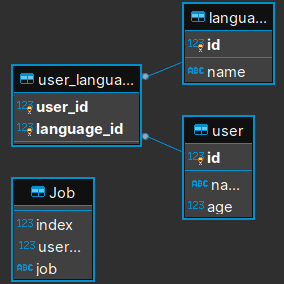
В прошлой статье мы создали несколько таблиц с отношением один-ко-многим: пользователь (User) может знать несколько языков (Language). Рисунок ниже показывает ER-диаграмму в DBeaver.
Чтобы вывести тех пользователей, которые знают иностранный язык, нужно написать следующий Python-код:
import sqlite3
con = sqlite3.connect("test.db")
cur = con.cursor()
cur.execute("""
SELECT user.name, language.name
FROM user, language, user_language
WHERE (user.id = user_language.user_id AND
language.id = user_language.language_id)
""").fetchall()
И на выходе получится следующий результат:
[('Sasha', 'spanish'),
('Vova', 'english'),
('Vova', 'spanish'),
('Anna', 'french')]
А теперь рассмотрим, как можно настроить взаимодействие между SQLite и Pandas.
Считываем записи из базы данных в DataFrame
Мы можем получить записи из базы данных и записать их в DataFrame — объект для представления табличных данных в Pandas. Это очень полезно, поскольку в Data Science данные иногда приходится хранить в базах данных, а работать с ними в Python.
Для получения записей из базы данных используется метод read_sql, который принимает в качестве аргументов запрос и соединение. В Python это реализуется следующим образом:
import pandas as pd
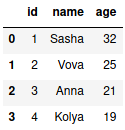
df = pd.read_sql("SELECT * FROM user", con)
Полученный DataFrame изображен на рисунке ниже.
Можно также реализовать запрос, который выводит данные из двух таблиц User и Language:
sql = """
SELECT user.name, language.name
FROM user, language, user_language
WHERE (user.id = user_language.user_id AND
language.id = user_language.language_id)
"""
df = pd.read_sql(sql, con)
В результате DataFrame с этим запросом выглядит вот так:
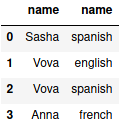
Считываем данные из DataFrame в базу данных
Теперь, наоборот, экспортируем записи DataFrame в базу данных. Создадим DataFrame с новыми пользователями:
df = pd.DataFrame({
"id": [5, 6],
"name": ["Sveta", "Galya"],
"age": [41, 55]
})

Полученный DataFrame можно добавить к таблице User. Для этого используется метод to_sql. Аргумент index равен False, поскольку по умолчанию Pandas считает свою индексацию как отдельный атрибут, а аргумент if_exists="append" используется, чтобы добавить новые записи к старым.
df.to_sql("user", con=con, if_exists="append", index=False)
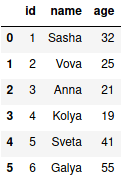
Написав запрос на вывод всех пользователей, получится следующая картина:
pd.read_sql('''
SELECT *
FROM user
''', con)
Создаем новую таблицу в Pandas
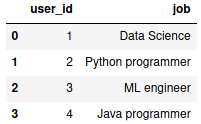
Помимо добавления данных из Pandas в существующую таблицу, можно создать новую таблицу. Но Pandas не дает возможности использовать отношения (один-к-одному, один-ко-многим и т.д.), поэтому это будет отдельная таблица. Для примера создадим DataFrame с занимаемыми должностями:
df_job = pd.DataFrame({
"user_id": [1, 2, 3, 4],
"job": ["Data Science", "Python programmer",
"ML engineer", "Java programmer"]
})
Применив метод to_sql, мы получим новую таблицу без какого либо отношения. Ниже показаны Python-код и рисунок с ER-диаграммой.
df_job.to_sql("Job", con)
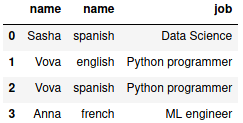
Тем не менее, запросы к новой и старым таблицам все также можно совершать. Вот так, например, выглядит запрос в Python для вывода имени, знания языков и должности:
sql = """
SELECT user.name, language.name, user_job.job
FROM user, user_language, language, user_job
WHERE (user.id = user_language.user_id AND
language.id = user_language.language_id AND
user.id = user_job.user_id)
"""
pd.read_sql(sql, con)
Несмотря на то, что здесь рассматривался пример интеграции Pandas именно c SQLite, можно также интегрировать Pandas с любой другой СУБД.
Использованный в статье код доступен в репозитории на Github. А приобрести практические навыки работы с данными в Pandas и SQL на практических примерах Data Science проектов, вы сможете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Источники