
Данные для Data Science проектов можно получать ото всюду, в том числе и с веб-сайтов, например, страниц Википедии. Сегодня мы расскажем, как извлечь все таблицы из веб-страницы с помощью функции read_html Python-библиотеки Pandas, а также обработать полученные данные, включая нормализацию и приведение типов.
Как работает парсинг сайтов
В Pandas есть функция — read_html, которая использует одну из библиотек для парсинга веб-страниц: BeautifulSoup4, html5lib или lxml. По умолчанию в Pandas стоит lxml, однако, в случае ее отсутствия будет применяться другая. Поэтому для корректного выполнения хотя бы одна из них должна быть установлена. Установить lxml можно, выполнив следующую операцию в командной строке:
pip install lxml
Одна из перечисленных Python-библиотек ищет на указанной веб-странице все таблицы под тэгом <table>. Внутри таблицы могут быть заголовки и сами данные под тэгами <th> и <td>. В результате, Pandas-функция read_html ищет все таблицы на сайте и возвращает их в виде списка в формате DataFrame.
Не всегда все таблицы получается получить в приемлемом виде: могут быть проблемы с заголовками, типами данных, кодировкой. Поэтому прежде всего их необходимо будет обработать. Мы покажем, как в Python получить таблицы с Википедии со страницы пандемии COVID-19 и обработать их.
Извлечение таблиц
Вызовем функцию read_html, передав аргументом ссылку на страницу. Ниже приведён код в Python. Всего библиотека lxml нашла 17 таблиц.
import pandas as pd # Пандемия_COVID-19 tables = pd.read_html( 'https://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D0%BD%D0%B4%D0%B5%D0%BC%D0%B8%D1%8F_COVID-19') len(tables) # 17
Выберем на странице таблицу со статистикой заболеваний по странам и территориям. Поскольку искать её среди 17 таблиц утомительно, мы воспользуемся регулярными выражениями. Для этого передадим аргумент match с подходящим регулярным выражением, например, «стран». Код на Python выглядит следующим образом:
tables = pd.read_html(
'https://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D0%BD%D0%B4%D0%B5%D0%BC%D0%B8%D1%8F_COVID-19',
match='стран')
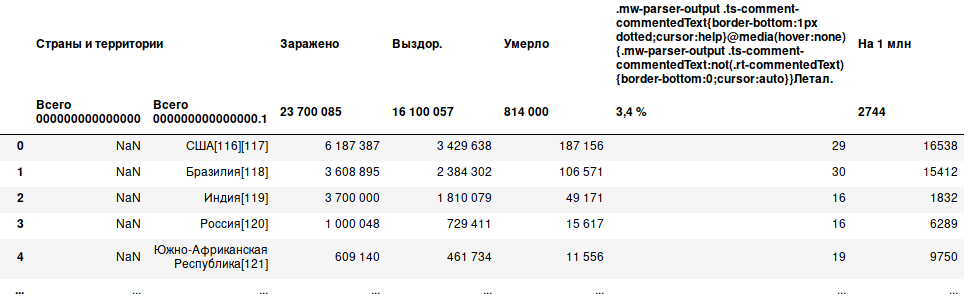
Всего нашлось 3 таблицы, которые содержат в своем заголовке слово «стран». Нужная нам находится под индексом 1. Однако таблица выглядит не лучшим образом: появился ещё один столбец, заполненный только NaN, название одного из столбцов содержит HTML-код, возможно нам не требуется результирующий заголовок на 2 уровне и ещё много чего. Исправим это.
Обрабатываем таблицы
В первую очередь избавимся от лишнего столбца, вызвав метод drop. Ещё мы удалим последние две строчки под номером 254 и 255, так как они содержат примечания, а не данные. Ниже представлен код на Python. Поскольку у нас двухуровневый заголовок, то и в аргументе он указывается в виде кортежа (tuple).
df.drop(('Страны и территории', 'Всего 000000000000000'), axis=1, inplace=True)
df.drop(axis=0, index=[254, 255], inplace=True)
Теперь отбросим нижний результирующий уровень, вызвав метод droplevel, а после этого переименуем нечитаемое название одного из столбцов в нормальное с помощью метода rename. В Python это выглядит следующим образом:
df.columns = df.columns.droplevel(-1)
df.rename(columns={'.mw-parser-output .ts-comment-commentedText{border-bottom:1px dotted;cursor:help}@media(hover:none){.mw-parser-output .ts-comment-commentedText:not(.rt-commentedText){border-bottom:0;cursor:auto}}Летал.': 'Летал.'}, inplace=True)
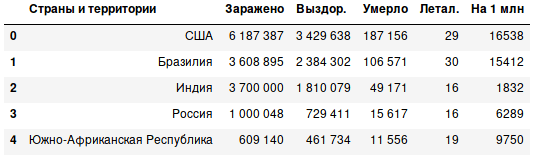
Кроме того, следует убрать источники, заключённые в квадратные скобки. Для этого мы воспользуемся методом replace, указав регулярное выражение и regex=True. Теперь таблица выглядит более приемлемо.
df.replace({'\[[0-9]+\]': ''}, regex=True, inplace=True)
Нормализация и указание типов
Часто типом таблиц после парсинга веб-страниц является строка (str), которая в DataFrame указывается как object. Кроме того, может быть указана неизвестная кодировка. Это также следует исправить.
Исходная таблица включает подразделы: непризнанные государства, морские суда и т.д. Каждый подраздел имеет заголовок «Справочно» или «Морские суда». Мы воспользуемся этой информацией и разделим DataFrame. Прежде всего определим индексы этих заголовков и в цикле будем делить DataFrame на части, причем мы добавляем к индексу 1 каждый раз, чтобы не включать сам заголовок. Вот так выглядит Python-код:
indices = df[
(df['Страны и территории'].str.contains('Справочно') |
df['Страны и территории'].str.contains('Морские суда'))
].index
dfs = []
cur = 0
for idx in indices:
if idx != indices[-1]:
part = df.iloc[cur:idx, :]
else:
part = df[idx+1: ]
cur = idx + 1
dfs.append(part)
Строки могут содержать нечитаемые символы, поэтому их следует нормализовать. Мы нормализуем по типу NFKC. После нормализации следует привести к соответствующему типу данных, например, float32. Но прежде всего нужно избавиться от нечисловых символов, а пробелы и «н/д» нужно заменить на Nan. В итоге, для одного из DataFrame код на Python имеет следующий вид:
temp_df = dfs[0]
temp_df.columns = temp_df.columns.str.normalize('NFKC')
cols = temp_df.columns.drop(temp_df.columns[0]) # Выкинуть “Страны и территории”
for col in cols:
temp_df.loc[:, col] = temp_df.loc[:, col].str.normalize('NFKC')
temp_df.loc[:, col] = temp_df.loc[:, col].replace(
{' ': np.nan, 'н/д': np.nan}, regex=True
).astype('float32')
Весь приведенный код можно посмотреть в репозитории на Github.
А о том, как парсить сайты и обрабатывать полученные данные в Pandas на практических примерах Data Science, вы узнаете на нашем специализированном курсе по Python «DPREP: Подготовка данных для Data Mining на Python» в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.

