
В рамках анализа временных рядов в большинстве случаев полезнее визуализировать, как данные меняются с течением времени. Сегодня расскажем о 4-х полезных диаграммах для визуализации временных рядов в Python. Читайте в этой статье: как найти разницу между значениями, посчитать процентное изменение, построить кумулятивную кривую и тепловую карту в Python
Датасет с ценами на акции
Воспользуемся датасетом с данными фондового рынка S&P500. Он содержит цены на акции при открытии, закрытии, а также самое высокое и низкое значение с 2006 по 2017 года. Следующий код на Python показывает инициализацию датасета:
import pandas as pd link = "https://raw.githubusercontent.com/rashida048/Datasets/master/stock_data.csv" df = pd.read_csv(link, parse_dates=True, index_col="Date") df.head()
Open High Low Close Volume Name Date 2006-01-03 39.69 41.22 38.79 40.91 24232729 AABA 2006-01-04 41.22 41.90 40.77 40.97 20553479 AABA 2006-01-05 40.93 41.73 40.85 41.53 12829610 AABA 2006-01-06 42.88 43.57 42.80 43.21 29422828 AABA 2006-01-09 43.10 43.66 42.82 43.42 16268338 AABA
Разность между значениями
Чтобы посмотреть, как менялась цена на акцию с течением времени, полезно рассмотреть разницу значений в разные промежутки времени. Применительно к нашему датасету выведем разницу между ценой при закрытии текущего дня и предыдущего. В Python-библиотеке Pandas это можно сделать двумя способами: с помощью метода sub или diff. Первый метод sub принимает Series или DataFrame, с которым нужно вычислить разницу. А чтобы отнять значения предыдущего дня, используйте метод shift (свдиг). Пример на Python для подсчета разницы временных рядов со значениями цены закрытия:
df['Change'] = df.Close.sub(df.Close.shift()) df['Change'].plot(figsize=(10, 6))
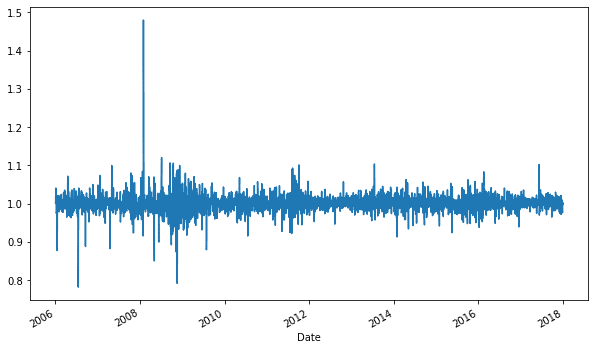
Второй способ с использованием метода diff ещё проще, а результат тот же. Но, в отличие от sub, который может отнимать от любого переданного параметра, diff работает только со значениями собственного атрибута:
df.Close.diff().plot(figsize=(10, 6))
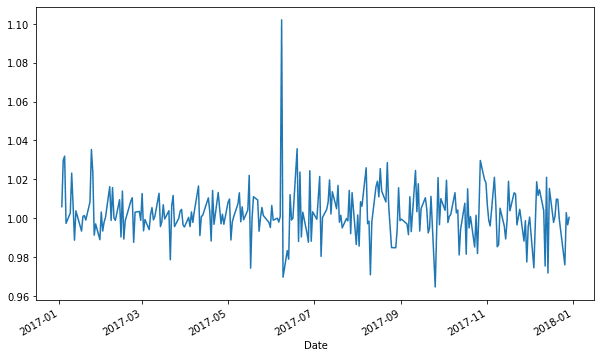
Можно также уменьшить частоту временного промежутка до одного года. Например, следующий пример на Python служит для визуализации изменения цены на акцию в 2017 году:
df['2017']['Change'].plot(figsize=(10, 6))
Процентное изменение
Кроме разницы между значениями можно использовать деление. Оно позволяет узнать во сколько раз меняется значение атрибута с течением времени. В Pandas для этого есть метод div. Однако более полезным и интерпретируемым инструментом является процентное изменение временных рядов. Оно вычисляется как отношение между текущим и предыдущим значением в процентном соотношение (нужно ещё домножить на сто). Пример того, как можно построить процентное изменение временных рядов в Python:
import matplotlib.dates as mdates
ddf = df[df.index.year == 2017]
ddf.loc[:, 'pct_change'] = ddf.Close.pct_change() * 100
fig, ax = plt.subplots(figsize=(8,4))
plt.xticks(rotation=45)
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=12))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y"))
ax.bar(ddf.index,
ddf.loc[:, 'pct_change'])
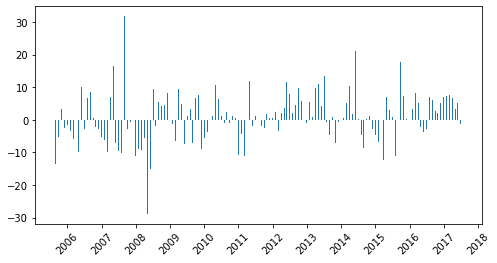
MonthLocator необходим для отображения интервалов в виде года на оси Х, а DateFormatter в каком виде даты должны отображаться.
Кумулята в Pandas
Также на графиках изменений временных рядов можно добавить кумулятивную кривую, отражающая степень накопления предыдущих значений. Для этой цели используется метод expanding. Например, в Python построим обычную зависимость между самой высокой ценой (High) и временем, а также добавим кумулятивные кривые среднего значения и стандартного отклонения.
fig, ax = plt.subplots() ax = df.High.plot(label='High') ax = df.High.expanding().mean().plot(label='High expanding mean') ax = df.High.expanding().std().plot(label='High expanding std') ax.legend()
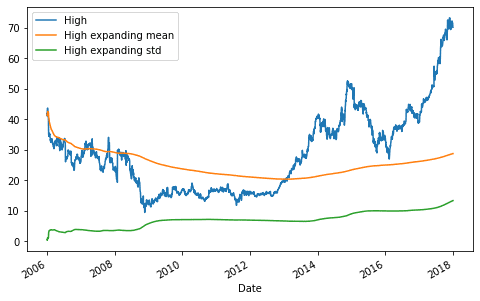
Посмотрите на ежедневные и кумулятивные средние значения. В конце 2017 года ежедневные значения показывают огромный всплеск. Но на кумулятивной кривой со средними не наблюдается подобного скачка, т.е. в глобальном смысле изменение не такое резкое. Вероятно, анализ данных за 2017 год покажет более детальную кумулятивную кривую.
Тепловая карта (heatmap)
В рамках визуализации временных рядов полезными являются тепловые карты (heatmap). Для начала на основе наших данных построим таблицу зависимости цены открытия в заданном году и месяце. Для этого воспользуемся функцией pivot_table. А чтобы отображать месяцы в виде аббревиатур, а не чисел, используется стандартный Python-модуль calendar.
import calendar
df['month'] = df.index.month
df['year'] = df.index.year
all_month_year_df = pd.pivot_table(df, values="Open",
index=["month"],
columns=["year"],
fill_value=0)
month_index = [month for month in calendar.month_abbr if month]
all_month_year_df = all_month_year_df.set_index([month_index])
all_month_year_df
year 2006 2007 2008 ... 2015 2016 2017 Jan 38.245500 27.990500 21.926667 ... 48.310500 30.250526 42.256000 Feb 33.141579 30.297368 28.884000 ... 43.861579 29.107000 44.916316 Mar 31.333478 30.549545 28.070000 ... 43.929091 34.064545 46.230870 ... Nov 26.993810 27.243810 11.321579 ... 33.602500 40.900000 71.223333 Dec 26.371500 24.540500 12.266364 ... 33.944091 39.742857 70.144500
А вот для построения тепловой карты (heatmap) в Python используется библиотека Seaborn. В результате код на Python для визуализации временных рядов на тепловой карте выглядит так:
import seaborn as sns
fig, ax = plt.subplots(figsize=(12,6))
ax = sns.heatmap(all_month_year_df, cmap='RdYlGn_r', robust=True,
fmt='.2f', annot=True, linewidths=.5, ax=ax,
cbar_kws={'shrink':.8, 'label':'Open'})
ax.set_yticklabels(ax.get_yticklabels(), rotation=0, fontsize=10)
plt.title('Average Opening', fontdict={'fontsize':18})
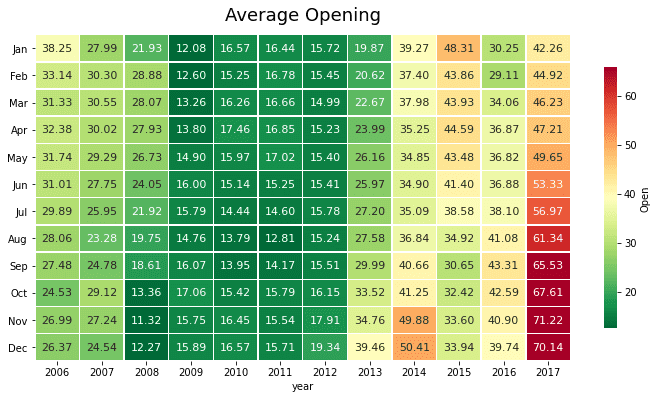
Как видим, конец 2017 года обозначился высоким подъемом цен. С другой стороны, в период 2009-2012 ситуация была стабильной, и цены ниже по сравнению с предыдущими годами. Видимо, большое влияние на цены S&P500 повлиял кризис 2008 года, и потребовалось 3 года для восстановления.
Больше подробностей об анализе временных рядов и подготовке данных на примерах прикладных задач Data Science на языке Python вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации Data Scientist’ов и IT-специалистов в Москве.
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.sub.html
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.pct_change.html
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.expanding.html

