Визуализация данных является одной из первоочередных задач Data Science и Machine Learning. Графическое представление помогает увидеть зависимости между переменными, будь то оценка эпидемии, отношение рубля к доллару, значение ВВП в разных странах, уровень ДТП в регионах или изменение качества модели ML-модели с каждой эпохой обучения.
В этой статье мы расскажем вам о 5 видах графиках: диаграмме рассеяния, линейном, барном, гистограмме и ящике с усами. В качестве инструмента визуализации будем пользоваться библиотекой Python — matplotlib, чтобы ее скачать, введите в командной строке:
pip install matplotlib
Пробуем на вкус вино — подбор датасета
Для примера возьмем датасет с отзывами о вине, доступный для скачивания на сайте Kaggle — онлайн-площадке для соревнований по машинному обучению. Данный датасет содержит информацию о качестве вина, протестированные 19-ю экспертами. Каждое вино имеет свою цену, родину, описание и отзыв с балами (от 0 до 100) от эксперта.
В первую очередь импортируем библиотеки:
import pandas as pd import matplotlib.pyplot as plt
Заметим, мы импортируем только модуль pyplot из matplotlib, так как именно он обеспечивает необходимыми графиками.
Далее, также как и в нашей предыдущей статье c помощью pandas создадим DataFrame, отбросив некоторые атрибуты для экономии места:
data = pd.read_csv('winemag-data-130k-v2.csv')
data = data.drop(['description', 'title', 'Unnamed: 0'], axis=1)
data.head()
Данные выглядят следующим образом:
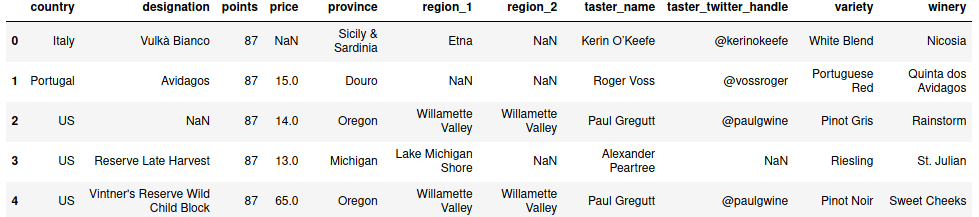
Ключевыми атрибутами являются price — цена и points — балы. А теперь начнем построение графиков.
Диаграмма рассеяния (Scatter plot) в matplotlib
Диаграмма рассеяния отображает пространство одних вещественных чисел в пространстве других вещественных чисел. Иными словами, каждая точка одного атрибута соответствует каждой точке другого. В matplotlib он имеет название scatter:
plt.xlabel('points')
plt.ylabel('price')
plt.scatter(x=data['points'], y=data['price'])
xlabel и ylabel служат для обозначения осей x и y, соответственно. В качестве аргументов принимает одномерные массивы x и y. Сам график выглядит следующим образом:
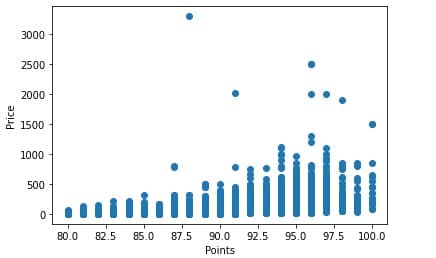
Диаграмма рассеяния может служить для визуализации линейных моделей машинного обучения, такие как линейная регрессия или метод опорных векторов. Исходя из этого графика, можно заметить, что баллы являются дискретными данными, поэтому линейная регрессия здесь неуместна.
Линейный график (plot) в matplotlib
Линейный график необходим для построения линии от точки к точке. В matplotlib.pyplot он называется plot:
d = data.groupby('points').mean()
plt.xlabel('points')
plt.ylabel('Средняя цена')
plt.plot(d.index, d.values)
Расположенная выше диаграмма рассеяния имеет слишком много точек для каждого бала. Поэтому было решено с группировать датафрейм по баллам методом groupby и взять для каждого бала среднюю цену. Заметим, после группировки обращение к балам (points) осуществляется через атрибут index. Функция plot также принимает в качестве аргументов x и y. График выглядит так:
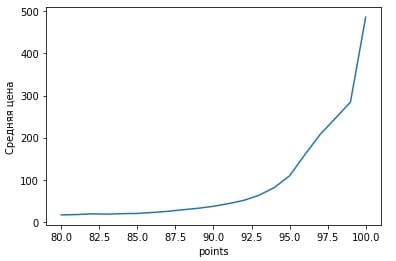
Как видим, чем выше цена на вино, тем больше балов ставили эксперты. Вы можете увидеть подобный график в машинном обучении, например, как в нейронной сети измененяетя точность модели с увеличением эпохи обучения.
Барный график (bar plot)
Барный график представляет собой столбчатую диаграмму, которая показывает количественное отношение категориального признака. Например, выберем 7 стран, в которых производится большое число винных изделий. Каждый бар будет представлять страну, а высота определять количество вин, произведенных в этой стране. В matplotlib барный график называется bar, принимающий в качестве аргументов x — массив категорий и height — массив значений этой категории:
countries = data['country'].value_counts().head(7)
plt.xlabel('Cтрана')
plt.ylabel('Количество вин')
plt.bar(x=countries.index, height=countries.values)
Метод value_counts считает количество значений каждой категории, и оттуда мы выбираем 7 первых (подсчитанные сортируются по убыванию). И вот так выглядит график:
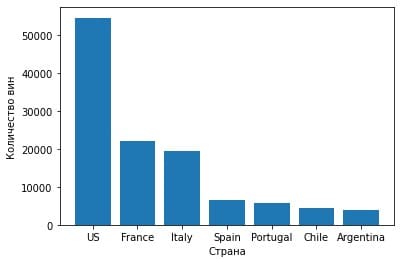
Как видно, США производит больше вин, чем любая другая страна в этом датасете.
Гистограмма (hist plot)
Для отображения частотного показателя анализируемого атрибута используется гистограмма. Гистограммы похожи на барный график за исключением того, что вместо категориальных признаков берутся числовые, поэтому используются диапазоны значений. Кроме того, с помощью гистограмм можно построить плотность распределения. Так и сделаем. В matplolib гистограмма имеет название hist:
plt.xlabel('points')
plt.ylabel('Вероятность')
plt.hist(x=data['points'], bins=40, density=True)
В качестве аргумента он принимает x, как массив значений, bins — количество значений, разбиваемых на диапазоны, denisty, равное True, представляет данные в виде плотности распределения. Сам график в Jupyter Notebook:
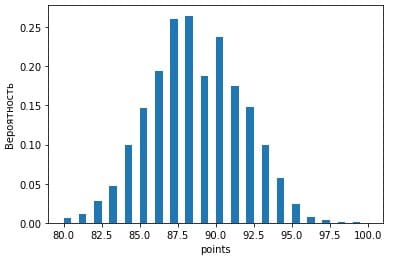
Прошу заметить, функция hist также вернула bins, которых насчитывается 41:
array([ 80. , 80.5, 81. , 81.5, 82. , 82.5, 83. , 83.5, 84. , 84.5, 85. , 85.5, 86. , 86.5, 87. , 87.5, 88. , 88.5, 89. , 89.5, 90. , 90.5, 91. , 91.5, 92. , 92.5, 93. , 93.5, 94. , 94.5, 95. , 95.5, 96. , 96.5, 97. , 97.5, 98. , 98.5, 99. , 99.5, 100. ]), <a list of 40 Patch objects>)
hist разбивает числовой атрибут на равные промежутки. Например, здесь значения взяты по 0.5. Таким образом, получается близкое к 40 значений атрибута, после берутся пары из этих значений: [80, 80.5), [80.5, 81), [81, 81.5) и так далее. В итоге получается 20 столбцов.
Ящик с усами (box plot)
Ящик с усами, он же диаграмма размаха, можно сравнить с плотностью распределения. Он тоже показывает диапазон значений, лежащих около среднего. Помимо прочего, с его помощью можно определить выбросы — те данные, которые находятся далеко от среднего. Удаление выбросов является важным шагом подготовки модели машинного обучения, что очень важно для Data Scientist’a. В matplotlib ящик с усами называется boxplot:
plt.boxplot(x=data['points'])
Основным аргументом является x, принимающий массив анализируемых числовых значений. Вид графика представлен следующим образом:
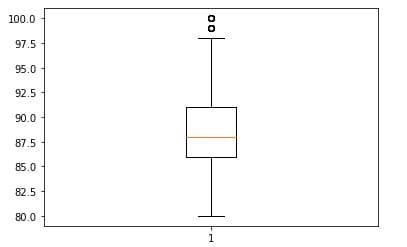
Нижняя и верхняя границы соответствуют 25% и 75% квартилям, соответственно; горизонтальная черта внутри ящика показывает среднее значение; а концы “усов” определяются, как края статистически значимой выборки [1].
Можно заметить, на графике имеются две точки — это выбросы. При желании от них можно избавится, если они слишком сильно влияют на обучение модели, с помощью того же метода drop в pandas.
Исходный код вместе с Jupyter Notebook выложен в репозиторий на github.
Методы визуализации могут стать визитной карточкой вашего проекта. Они позволяют наиболее полно понять данные сквозь огромное количество цифр. В нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве вы познакомитесь с качественным применением визуализации в Python, поймете когда и где это лучше применять. В следующей статье мы расскажем как строить эти же самые графики с помощью pandas, не импортируя matplotlib.
Cмотрите также:
Курс VIP: Визуализация данных на языке Python